
Few-shot Periodic Video Image Segmentation Based on LSTM and Cross-attention Mechanism
-
摘要:
随着现代视频技术的发展,周期运动视频图像分割在运动分析、医学影像等领域中具有重要应用。本文基于深度学习技术设计一种新颖的周期性运动检测和分割网络,结合卷积长短期记忆网络(ConvLSTM)和交叉注意力机制,只需要相对较少的标签,便能够有效捕获视频序列中感兴趣对象的时空上下文信息、跨帧一致性并进行精确分割。实验结果表明,少样本标签情况下,本文方法在周期性运动视频数据集上表现出色。在普通视频中,平均区域相似度和轮廓相似度分别为67.51% 和72.97%,相较于传统方法普遍提升1%~1.5%。在医学视频中,平均区域相似度和轮廓相似度分别为59.93% 和90.56%,在区域相似度上,相较于DAN和Unet分别提升12.92% 和8.85%。在轮廓相似度上,分别提升20.09% 和12.89%,具有更高的准确性和稳定性。
Abstract:With the development of modern video technology, periodic motion video image segmentation has important applications in motion analysis, medical imaging, and other fields. In this study, we designed a novel periodic motion detection and segmentation network based on deep learning technology, which combines the convolutional long short term memory network (ConvLSTM) and cross-attention mechanism. With relatively few labels, we can effectively capture the spatiotemporal context information of the objects of interest in the video sequence, achieving cross-frame consistency and accurate segmentation. Experimental results show that the proposed method performs well on periodic motion video datasets with few sample labels. In an ordinary video, the average region similarity and contour accuracy were 67.51% and 72.97%. respectively, which improved by 1%~1.5% than those obtained with the traditional method. In medical videos, the average region similarity and contour accuracy were 59.93% and 90.56%, respectively. Compared with DAN and Unet, the proposed method increased the regional similarity by 12.92% and 8.85%, whereas it improved the contour accuracy by 20.09% and 12.89%, respectively, thus achieving higher accuracy and stability.
-
Keywords:
- deep learning /
- video segmentation /
- image segmentation /
- LSTM /
- cross-attention mechanism
-
视频对象分割(video object segmentation,VOS)作为视频检索、编辑等各种视频应用的重要步骤,越来越受到人们的关注。基于用户交互,现有的VOS算法有两种常见的设置:无监督VOS和半监督VOS。无监督VOS[1-8]在没有人为干预的情况下,直接分割视频中的主要对象,这些物体通常位于显著区域。而半监督VOS[9-15]给出第1帧的ground truth分割,并将标记的对象信息传播到后续帧中。然而,它需要对每个单独视频的第1帧进行像素级注释,这限制了处理大量视频的可扩展性。虽然交互式VOS[16-17]进一步将所需人力减少到几个笔画,但所提供的信息对于跨帧分割可能过于粗糙。为了在语义分割和跨视频处理之间进行权衡,最近的研究[18-20]利用了自然语言和类标签等新的交互作用。
周期运动视频是指在视频序列中呈现明显重复运动的场景,如人体行走、交通工具移动或机械装置的循环往复动作。周期运动视频对象分割是一个重要技术,专注于从这些视频中提取和跟踪具有周期模式的运动对象。通过分析视频帧序列中的运动模式,该技术能够识别并分离出具有重复运动的对象,为视频监控、运动分析、虚拟现实和医学影像[21-24]等领域提供重要支持。
借助计算机视觉(computer vision,CV)和深度学习(deep learning,DL)技术,周期运动视频对象分割不仅提高了对复杂动态场景的理解能力,还为视频内容的深入理解和应用提供了更为精细的解决方案。随着网络视频数量的迅速增加,周期运动视频对象分割在视频检索、编辑等方面逐渐成为备受关注的研究热点。
1. 相关工作
本文旨在解决少样本周期视频图像分割的问题,这是一个尚未完全解决的挑战。本文提出一种新的方法,通过利用带有注释的支持图像来增强在不同场景下同类目标的分割结果。这些支持图像可以在查询视频之外随机选择,从而提高模型的泛化能力,能够在语义分割和跨视频处理之间取得平衡,满足实际情况下网络视频激增的应用需求。
本文的核心技术包括卷积长短期记忆网络(convolutional LSTM network,ConvLSTM)和交叉注意力机制(cross-attention mechanism)。ConvLSTM能够有效地捕捉视频序列中的长期依赖关系,而交叉注意力机制则能够帮助模型更好地理解不同场景下的目标。因此本文的方法在少样本周期视频图像分割任务上取得了很好的效果。
1.1 卷积长短期记忆网络
卷积长短期记忆网络[25]是一种将卷积神经网络(convolutional neural networks,CNN)[26]和长短期记忆(long short-term memory,LSTM)[27]相结合的深度学习模型,适用于时间序列图像(如视频)的建模。与传统全连接LSTM相比,ConvLSTM在处理时空相关性方面具有更强的性能,其创新之处在于将卷积操作引入LSTM结构中,以更有效地捕捉时空上下文信息。
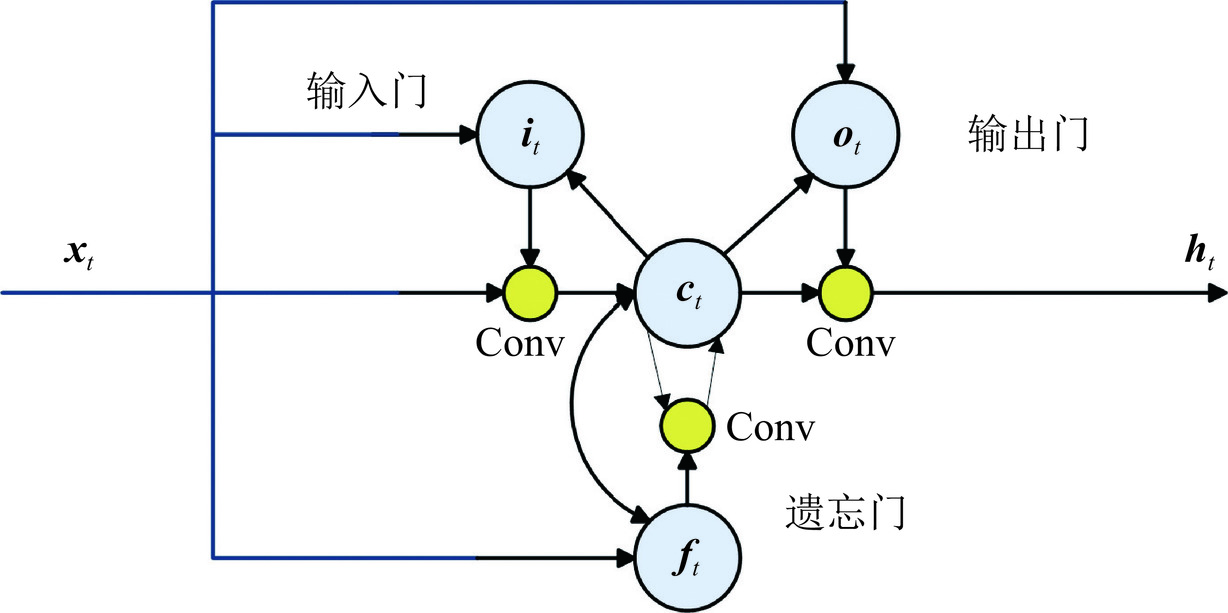
在ConvLSTM中,除了传统的输入门、遗忘门和输出门外,还存在卷积操作。每个ConvLSTM单元由一个细胞状态(cell state,C)和一个隐藏状态(hidden state,H)组成,其中细胞状态类似于传统LSTM中的记忆细胞。
当输入特征映射进入ConvLSTM单元时,卷积操作可以有效地捕捉空间信息,并与LSTM结构相结合,使得ConvLSTM能够处理时间序列图像。在ConvLSTM中,输入门、遗忘门和输出门的计算方式与传统LSTM相似,但是它们与卷积操作结合,使得ConvLSTM能够更好地处理时空相关性。
ConvLSTM的记忆门允许细胞状态逐渐积累信息,以适应时间序列图像中的长期依赖关系。当输入门被激活时,新的信息被添加到细胞状态中;而当遗忘门被激活时,过去的记忆则被遗忘。最终,输出门和当前细胞状态经过卷积,得到了ConvLSTM的输出。
通过将LSTM单元中的全连接层替换为输入门、遗忘门和输出门的卷积运算,构造ConvLSTM单元如图1所示,ConvLSTM方程如式(1)所示,
$$ \left\{ \begin{aligned} & {\boldsymbol{i}_t} = \delta \Big( {{\boldsymbol{W}_{xi}}*{\boldsymbol{x}_{_t}} + {\boldsymbol{W}_{hi}}*{\boldsymbol{h}_{_{t - 1}}} + {\boldsymbol{W}_{ci}} \circ {\boldsymbol{c}_{_{t - 1}}} + {\boldsymbol{b}_i}} \Big) \\ &{\boldsymbol{f}_t} = \delta \Big( {{\boldsymbol{W}_{xf}}*{\boldsymbol{x}_{_t}} + {\boldsymbol{W}_{hf}}*{\boldsymbol{h}_{_{t - 1}}} + {\boldsymbol{W}_{cf}} \circ {\boldsymbol{c}_{_{t - 1}}} + {\boldsymbol{b}_f}} \Big) \\ & {\boldsymbol{c}_t} = {\boldsymbol{f}_t} \circ {\boldsymbol{c}_{_{t - 1}}} + {\boldsymbol{i}_t} \circ \tanh \Big( {{\boldsymbol{W}_{xc}}*{\boldsymbol{x}_{_t}} + {\boldsymbol{W}_{hc}}*{\boldsymbol{h}_{_{t - 1}}} + {\boldsymbol{b}_c}} \Big) \\ & {\boldsymbol{o}_t} = \delta \Big( {{\boldsymbol{W}_{xo}}*{\boldsymbol{x}_{_t}} + {\boldsymbol{W}_{ho}}*{\boldsymbol{h}_{_{t - 1}}} + {\boldsymbol{W}_{co}} \circ {\boldsymbol{c}_{_{t - 1}}} + {\boldsymbol{b}_o}} \Big) \\ & {\boldsymbol{h}_t} = {\boldsymbol{o}_t} \circ \tanh ({\boldsymbol{c}_t}) \end{aligned}\right. \text{,} $$ (1) 其中, * 表示卷积算子,而
$ \circ $ 表示Hadamard积。Wx、Wh和Wc表示相应门的卷积核。xt是ConvLSTM模块的输入,ht表示隐藏的输出。ConvLSTM通过将卷积操作与LSTM结构相结合,能够更有效地处理时空序列图像,并在时间序列图像建模任务中能够取得显著的性能提升。
1.2 交叉注意力机制
交叉注意力机制[28-30]是一种重要注意力机制,常用于处理包含多个输入序列或模态(如文本和图像)的情况。与自注意力机制[31-32]不同,交叉注意力机制允许模型关注不同输入序列间的交叉关系,从而更好地捕获它们之间的语义相关性。
在交叉注意力机制中,通常存在两种类型的序列:查询序列和键值序列。查询序列通常是模型要关注的序列,而键值序列包含用于计算注意力权重的信息。例如,在将图像和文本进行关联时,文本可作为查询序列,而图像可作为键值序列。交叉注意力机制的核心思想是,对于查询序列中的每个元素,模型都会根据键值序列中的信息来计算其上下文表示。具体来说,对于查询序列中的每个元素,交叉注意力机制计算该元素与键值序列中每个元素之间的相似度,并根据这些相似度来计算加权和,从而获得该元素的上下文表示。这样,模型能够根据键值序列中的信息来调整查询序列中的表示,从而更好地捕获它们之间的语义关系。
交叉注意力机制在多模态任务中得到了广泛应用,例如图像标注、视觉问答和图像生成等领域。它能够有效地将不同模态的信息整合起来,提高模型对复杂任务的理解和处理能力。本文采用交叉注意力机制将近似类别或同类别不同环境的视频图像之间建立联系,从而增强在少样本新场景下的模型分割能力,提高了模型的泛化能力。
2. 基于LSTM与交叉注意力机制的分割模型
本文每个训练集合包括支持集和同类标签的查询集,每个支持集和查询集包含相同图片组个数,每个图片组包含当前帧以及前后两帧共3帧。支持集中每张图片在与查询集同类标签下都有一张标签,网络学习预测查询集中所有帧的预测标签。
2.1 周期计算
首先对视频数据序列估计周期,将视频中第1个周期序列用作训练集,后面的视频序列做测试集。由于周期运动从任一时刻开始,每经过一定时间,就恢复到开始时刻。因此对视频序列所有图像计算与第1帧的皮尔逊相关系数:
$$ {\rho _{{\boldsymbol{XY}}}} = \frac{{{{\mathrm{cov}}} ({\boldsymbol{X}},{\boldsymbol{Y}})}}{{{\sigma _{\boldsymbol{X}}}{\sigma _{\boldsymbol{Y}}}}} = \frac{{E\Big( {\Big( {{\boldsymbol{X}} - {\mu _{\boldsymbol{X}}}} \Big)\Big( {{\boldsymbol{Y}} - {\mu _{\boldsymbol{Y}}}} \Big)} \Big)}}{{{\sigma _{\boldsymbol{X}}}{\sigma _{\boldsymbol{Y}}}}} \text{,} $$ (2) 其中:
$ {\mu }_{{\boldsymbol{X}}} $ 和$ {\sigma }_{{\boldsymbol{X}}} $ 分别是$ \boldsymbol{X} $ 的均值和标准差,$ {\mu }_{{\boldsymbol{Y}}} $ 和$ {\sigma }_{{\boldsymbol{Y}}} $ 是$ \boldsymbol{Y} $ 的均值和标准差。对所得相关系数的时间序列记为T,进行归一化将序列映射到
$[-1,1] $ 之间:$$ {{T}} = \frac{{2\big( {{{T}} - {{{T}}_{\min }}} \big)}}{{{{{T}}_{\max }} - {{{T}}_{\min }}}} - 1 。 $$ (3) 然后将序列T在频谱分析,根据提取幅值频谱的峰值,以确定其具体周期,依据周期估计结果,将第1个周期序列作为训练集的查询集。
2.2 模型框架
模型主要由3个部分组成:编码器网络,LCA(LSTM与交叉注意力机制)模块和解码器网络(图2)。给定支持集的多个查询集作为输入,两个具有相同权重的编码器分别为支持集和查询集提取特征,对查询集特征通过ConvLSTM层增强时序相关特征,然后通过交叉注意力机制,计算支持集和查询集之间的相关性,得出注意力特征。将注意力特征与查询集特征连接起来,使用解码器来预测最终的分割结果。
ResNet-50(deep residual network)是一个经典的深度学习模型,在ImageNet数据集上取得了很好的性能,并且具有较深的网络结构,能够捕获更复杂的特征,从而在许多视觉任务中表现出色。先前工作[33]发现,在少样本场景中,深度学习网络高层的特征的泛化程度较低。因此,本文使用在ImageNet[34]上预训练的ResNet-50[35]以获得通用特征表示。
经过LCA模块处理后,将查询集的特征值先进行时序增强,再与注意特征连接起来,然后发送到解码器。本文基于上采样操作和跳跃连接来设计解码器。首先,对特征进行上采样,以恢复到输入图像的大小;同时,通过跳跃连接将查询帧的底层特征融合到上样本特征中;最终,通过解码器预测查询集的分割标签。
2.3 LCA模块
计算支持集和查询集图像之间的相关性通常涉及多对多关注矩阵的计算。本文通过两个较小矩阵乘积取代多对多注意力矩阵,并在其中嵌入ConvLSTM模块,增强了注意力矩阵的时序相关性。
如图3所示,将从编码层得到的查询集特征、支撑集特征,各自通过3个3×3卷积核,将特征通过线性变换,得到各自的q、k、
$ \boldsymbol{v} $ 。由于查询集是多视频帧具有时序相关性,因此将查询集输入到ConvLSTM模块中,以便模型能够更好地理解视频中的时序相关性和周期性。对时序性增强后的查询集q、k特征与支持集的k、$ \boldsymbol{v} $ 特征,计算注意力特征。域代理网络(domain agent network,DAN)[36]发现,从一帧学习到的注意力特征可近似于其他帧的注意特征。因此,采用中间帧作为一段视频的代替,保证学习到的注意力特征的信息性。通过采用查询集的q与k的中间帧和支持集的k与查询集q中间帧相乘的两个小矩阵乘法,代替查询集的q与支持集的k的大矩阵乘法。使计算复杂度从指数增加降为线性增加。
查询特征通过单个卷积层映射到查询
$ {\boldsymbol{q}}^{Q} $ 和键值对$ {\boldsymbol{k}}^{Q} $ -$ {\boldsymbol{v}}^{Q} $ 。类似地,支持特性映射到查询$ {{\boldsymbol{q}}}^{S} $ 和键值对$ {{\boldsymbol{k}}}^{S} $ -$ {{\boldsymbol{v}}}^{S} $ :$$ \left\{ {\begin{aligned} & {{{\boldsymbol{q}}^Q} \in {\mathbb{R}^{N \times {L_q}}},\;\;{{\boldsymbol{q}}^S} \in {\mathbb{R}^{M \times {L_q}}},\;\;{{{L}}_{\boldsymbol{q}}} = H \times W \times {C_q}} \\ &{{{\boldsymbol{k}}^Q} \in {\mathbb{R}^{N \times {L_k}}},\;\;{{\boldsymbol{k}}^S} \in {\mathbb{R}^{M \times {L_k}}},\;\;{{{L}}_{\boldsymbol{k}}} = H \times W \times {C_k}} \\ &{{{\boldsymbol{v}}^Q} \in {\mathbb{R}^{N \times {L_v}}},\;\;{{\boldsymbol{v}}^S} \in {\mathbb{R}^{M \times {L_v}}},\;\;{{{L}}_{\boldsymbol{v}}} = H \times W \times {C_v}} \end{aligned}} \right. 。 $$ (4) 将
$ {\boldsymbol{q}}^{Q} $ 和$ {\boldsymbol{k}}^{Q} $ 经过ConvLSTM模块后记为$ {\boldsymbol{q}}^{{Q}_{L}} $ 和$ {\boldsymbol{k}}^{{Q}_{L}} $ , 对$ {\boldsymbol{q}}^{{Q}_{L}} $ 和$ {\boldsymbol{k}}^{{Q}_{L}} $ 采用中间帧t作为一段视频的代替记为$ {\boldsymbol{q}}^{{Q}_{L}t} $ 和$ {\boldsymbol{k}}^{{Q}_{L}t} $ ,计算出$ {\boldsymbol{q}}^{{Q}_{L}} $ 与$ {\boldsymbol{k}}^{{Q}_{L}t} $ 的注意力矩阵$ {\boldsymbol{A}}^{Qt} $ 和$ {\boldsymbol{q}}^{{Q}_{L}t} $ 与$ {\boldsymbol{k}}^{S} $ 的注意力矩阵$ {\boldsymbol{A}}^{tS} $ :$$ {{\boldsymbol{A}}^{Qt}} = \sigma \left( {\frac{{{{\boldsymbol{q}}^{{Q_L}}}{{({{\boldsymbol{k}}^{{Q_L}t}})}^{\mathrm{T}}}}}{{\sqrt {{{\boldsymbol{C}}_k}} }}} \right);\;\;{A^{tS}} = \sigma \left( {\frac{{{{\boldsymbol{q}}^{{Q_L}t}}{{({{\boldsymbol{k}}^s})}^{\mathrm{T}}}}}{{\sqrt {{{\boldsymbol{C}}_k}} }}} \right) 。 $$ (5) 对得到的注意特征矩阵
$ {\boldsymbol{A}}^{Qt} $ 和$ {\boldsymbol{A}}^{tS} $ ,通过式(4)计算得到关注特征$ {\boldsymbol{v}}^{A} $ 。$$ {{\boldsymbol{v}}^A} = {\boldsymbol{A}}{{\boldsymbol{v}}^S} = {{\boldsymbol{A}}^{Qt}}{{\boldsymbol{A}}^{tS}}{{\boldsymbol{v}}^S} , $$ (6) 其中首先计算
$ {\boldsymbol{A}}^{tS}{\boldsymbol{v}}^{S} $ ,以避免存储和计算大矩阵A:$$ {\boldsymbol{A}} = \sigma \left( {\frac{{{\boldsymbol{q}}{{({\boldsymbol{k}})}^{\mathrm{T}}}}}{{\sqrt {{{\boldsymbol{C}}_k}} }}} \right) 。 $$ (7) 综上所述,本文模块的显存消耗和时间复杂度分别为
$ O\left(\big(N+M\big){\big(HW\big)}^{2}\right) $ 和$ O\left(\big(N+M\big){\big(HW\big)}^{2}C\right) $ ,而全阶注意模块的显存消耗和时间复杂度分别为$ O\left(\big(NM\big){\big(HW\big)}^{2}\right) $ 和$ O\left(\big(NM\big){\big(HW\big)}^{2}C\right) $ 。2.4 ConvLSTM模块
通过两个小矩阵乘法代替大矩阵乘法可降低计算复杂度,但是通过中间帧代替一段视频,随着查询集的增加,其时间相关性差异较大,限制了模型性能的增长,本文采用3D的ConvLSTM[37]可有效遏制这个问题。
对通过卷积层得到的q、k特征,按时间顺序分为3个图片组(图4)。从输入特征映射中复制初始存储单元,并根据特征的输入顺序更新存储单元。具体来说,从q、k特征中提取的特征映射x1中复制初始隐藏状态和存储单元。然后,ConvLSTM动态累积隐藏状态和来自存储单元的特征映射,计算出最后一个隐藏状态,即h3。将h1、h2、h3按时间顺序依次拼接,得到时序增强的特征。
3. 实验结果
3.1 周期数据集
本文基于Youtube-VIS建立训练集。该训练集由
2238 个Youtube视频组成,包含3774 个实例,涵盖40个类别。本文研究少样本周期视频分割问题,因此通过采用每个视频每个类别的前3或5个图片组作为训练集,其余作为测试集以达到少样本的目的。以5个图片组为例,支持集是增强被预测类别图像的分割效果,可由任意图片或者视频构成,不需具备周期性。因此,从单个类中随机抽取5个图像,并且取每个图像相邻两帧共计15帧作为支持集。查询集是被预测类别的图像,由于Youtube-VIS数据集不含周期视频,因此通过以下方式制作周期视频,3个图片组构造如图5(a)所示,5个图片组构造如图5(b)所示。以5个图片组为例,首先从与支持集的同类其他的完整视频中连续采样4个图像,再将第五张图像复制第一张图像制作成周期为4的视频图像序列,并取每个图像相邻两帧共计15帧,制成5个图片组的周期视频数据。为保证训练结果置信度,训练集和测试集保持独立。
3.2 实验环境
本文使用Adam(adaptive moment estimation)作为模型优化器。将学习率设置为10−5,交叉熵损失和IOU损失在
$ 5{{L}}_{\mathrm{c}\mathrm{e}}+{{L}}_{\mathrm{i}\mathrm{o}\mathrm{u}} $ 相结合用于训练,进行了100次迭代,批大小为2。本文实验环境都是在RTX2080 ti-11 G,Inter Xeon Silver4216 @ 2.10 GHz环境中训练测试。相较于大模型的视频图像分割背景下,本文模型更加轻量化,以极小的计算花费,利用视频图像分割任务中的时空上下文信息,并且首次针对周期视频分割任务提出了有效的解决方案,验证了本文模型在周期视频中的有效性。通过将批大小设为1,对比本文模型、DAN、ConvLSTM、ResNet模型的显存消耗。
由表1可见,本文模型训练时显存消耗6.27 Gbit,属于轻量型模型,可在
1080 ti-8 G及以上配置部署,相较于DAN模型仅增加了0.05 Gbit,相较于ConvLSTM、ResNet也只增加了1.4~1.8 Gbit。从性能来看,这些计算消耗的增加是必要的,具体性能分析在3.4中详细介绍。表 1 各模型的显存使用Table 1. Memory use of each model模型 显存/Gbits ResNet 4.83 ConvLSTM 4.46 DAN 6.22 Ours 6.27 3.3 评价指标
视频目标分割评价指标包括轮廓精确度(contour accuracy)和区域相似度(region similarity)。
区域相似度(region similarity):预测的掩膜M和真实标注G之间相交与联合区域之比,衡量了像素预测错误的程度。
$$ J = \frac{{{|\boldsymbol{M}} \cap {\boldsymbol{G}|}}}{{|{\boldsymbol{M }}\cup {\boldsymbol{G}}}|} 。 $$ (8) 轮廓准确度(contour accuracy):在预测的掩膜M和真实标注G的轮廓点集之间,计算基于轮廓的查准率
$ {P}_{c} $ 和召回率$ {R}_{c} $ ,两者的调和平均数即为准确度F,衡量了分割边界的准确程度。$$ F = \frac{{2{P_c}{R_c}}}{{{P_c} + {R_c}}} 。 $$ (9) 本文使用区域相似度(J)与轮廓相似度(F)来衡量模型性能。
3.4 普通视频应用
为了验证本文模型的有效性,与DAN、ConvLSTM、ResNet模型性能在区域相似度(
$ J $ )和轮廓相似度($ F $ )来进行对比。对查询集和支持集分别为3或5图像组的周期数据集对本文模型、DAN、ConvLSTM、ResNet模型进行训练和测试,结果如表2和表3所示。表 2 各模型在3图像组上的性能对比Table 2. Performance comparison of each model on 3 image groups模型 J F ResNet 0.553 0.592 ConvLSTM 0.530 0.569 DAN 0.637 0.687 Ours 0.642 0.691 表 3 各模型在5图像组上的性能对比Table 3. Performance comparison of ecah model on 5 image groups模型 J F ResNet 0.555 0.605 ConvLSTM 0.551 0.599 DAN 0.665 0.715 Ours 0.675 0.730 本文模型相对ResNet和ConvLSTM性能提升在10%左右,相对DAN模型也在两个指标平均提高了0.5% 到1.5%,并且随着查询集的增加(即从3增加到5),本文模型性能提高了3.28% 和3.91%,相比于DAN模型提升的2.8% 和2.87%,提升速度大于DAN模型。
本文模型在处理周期视频有一定的优越性,对查询集和支持集都为5图像组的周期数据集和非周期数据集上训练本文模型和DAN模型,结果如表4所示。
表 4 各模型在周期与非周期数据上性能对比Table 4. Performance comparison of each models on periodic and aperiodic data数据 模型 J F 非周期 DAN 0.680 0.728 非周期 Ours 0.671 0.719 周期 DAN 0.665 0.715 周期 Ours 0.675 0.730 本文对各模型分割结果进行详细对比。如图6和图7所示,ResNet存在大范围分割缺失情况,图6左边的鸭子存在多次未检测到,图7中蛇的躯干多张图分割缺失。ConvLSTM分割结果前后连续性较好,图6后3帧中,鸭头部分分割,图7中存在部分图片躯干未预测到,随着时间增加,分割效果逐渐变差。DAN在鸭子分割中形态较为完整,但分割结果前后独立,存在较多小面积细节分割缺失情况,图7中对蛇分割个别存在躯干分割缺失,躯干边界分割不够光滑。本文模型分割结果前后连续性较好,图6的鸭子和图7中的蛇存在个别细节分割缺失的问题,在图7中对蛇躯干部分分割较为光滑,基本不存在躯干缺失。
综上所述,本文模型分割结果均优于对比模型。
3.5 医学视频应用
进一步将本文模型应用于医学图像领域的鸡胚胎近似周期运动进行少样本视频图像分割。ResNet在医学图像的血管分割任务上,表现不是十分理想,并且U-Net[38]其独特的结构能够有效地满足医学图像中结构的大小变化、形状复杂性以及需要精确边缘定位的要求。将本文模型与DNA模型分别在ResNet和Unet编解码网络下进行对比实验。
由表5可见,本文模型在ResNet和Unet性能都优于DAN模块。在区域相似度上,本文模型在Unet网络下,相较于DAN提升了12.92%,相较于Unet提升了8.85%。在轮廓相似度上,本文模型相较于DAN提升了20.09%,相较于Unet提升了12.89%。
表 5 各模型鸡胚胎分割性能对比Table 5. Comparison of chicken embryo partitioning of each models模型 J F DAN+ResNet 0.140 0.075 LCA+ResNet 0.331 0.252 Unet 0.511 0.777 DAN+Unet 0.470 0.705 LCA+Unet 0.599 0.906 对预测结果进行可视化分析,如图8所示,对比了本文模型与Unet、DAN+Unet模型对不同数据扩增角度的数据集预测结果。由图8可见,3个模型对于鸡胚胎血管形状结构都能很好地学习到。在不同角度中,本文提出的LCA结合Unet后,分割的轮廓更加精准,边缘结果更加精细。在血管末端部分,本文模型能将毛细血管很好地与背景分割出来。Unet、DAN+Unet模型轮廓分割较模糊,边缘分割不准确,毛细血管分割存在粘连在一起的情况,相对于本文模型效果较差。
![]() 图 8 各模型鸡胚胎分割结果对比Figure 8. Comparison of chicken embryo segmentation results of each models
图 8 各模型鸡胚胎分割结果对比Figure 8. Comparison of chicken embryo segmentation results of each models4. 讨论
由以上结果可见,ResNet模型分割结果在时间连续性上较差,但能在连续分割过程中,不受之前分割结果影响,能发现之前帧未分割到的部分。ConvLSTM有效地结合了时序信息,在连续视频分割中不会存在大面积信息突然缺失行为,但随着时间增长,模型分割性能会不断降低。DAN模型形态分割较为完美,但是缺乏时间连续性,对连续视频在局部分割中仍存在信息缺失的问题。
本文模型有效地结合了时序信息,很少出现分割大范围缺失现象,降低了DAN模型在局部分割缺失的问题,相较于ConvLSTM模型,解决了随着时间增长模型分割性能越来越差的问题。但是在部分细节仍然存在缺失,对边缘轮廓更精确的分割,仍是该领域值得持续研究的问题。
5. 结论
本文提出了基于LSTM与交叉注意力机制的视频图像分割模型和制作周期视频图像序列的简洁方法,尝试解决少样本周期视频图像分割问题。
通过ConvLSTM与交叉注意力机制相结合,解决了DAN模型随着样本数增长,模型性能提升较差的问题。对周期视频分割问题提出有效的解决方案,以较小的计算代价处理少样本周期视频的图像分割问题,在少样本周期视频数据集中取得了良好结果。
-
![]()
图 8 各模型鸡胚胎分割结果对比
Figure 8. Comparison of chicken embryo segmentation results of each models
表 1 各模型的显存使用
Table 1 Memory use of each model
模型 显存/Gbits ResNet 4.83 ConvLSTM 4.46 DAN 6.22 Ours 6.27  下载: 导出CSV
下载: 导出CSV
表 2 各模型在3图像组上的性能对比
Table 2 Performance comparison of each model on 3 image groups
模型 J F ResNet 0.553 0.592 ConvLSTM 0.530 0.569 DAN 0.637 0.687 Ours 0.642 0.691
下载: 导出CSV
表 3 各模型在5图像组上的性能对比
Table 3 Performance comparison of ecah model on 5 image groups
模型 J F ResNet 0.555 0.605 ConvLSTM 0.551 0.599 DAN 0.665 0.715 Ours 0.675 0.730
下载: 导出CSV
表 4 各模型在周期与非周期数据上性能对比
Table 4 Performance comparison of each models on periodic and aperiodic data
数据 模型 J F 非周期 DAN 0.680 0.728 非周期 Ours 0.671 0.719 周期 DAN 0.665 0.715 周期 Ours 0.675 0.730
下载: 导出CSV
表 5 各模型鸡胚胎分割性能对比
Table 5 Comparison of chicken embryo partitioning of each models
模型 J F DAN+ResNet 0.140 0.075 LCA+ResNet 0.331 0.252 Unet 0.511 0.777 DAN+Unet 0.470 0.705 LCA+Unet 0.599 0.906
下载: 导出CSV
-
[1] BROX T, MALIK J. Object segmentation by long term analysis of point trajectories[C]//European conference on computer vision. Berlin, Heidelberg: Springer Berlin Heidelberg, 2010: 282-295. DOI: 10.1007/978-3-642-15555-0_21.
[2] LEE Y J, KIM J, GRAUMAN K. Key-segments for video object segmentation[C]//2011 International Conference on Computer Vision. IEEE, 2011: 1995-2002. DOI: 10.1109/iccv.2011.6126471.
[3] WANG W, SHEN J, PORIKLI F. Saliency-aware geodesic video object segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 3395-3402. DOI: 10.1109/cvpr.2015.7298961.
[4] DUTT J S, XIONG B, GRAUMAN K. Fusionseg: Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3664-3673. DOI: 10.1109/cvpr.2017.228.
[5] LI S, SEYBOLD B, VOROBYOV A, et al. Instance embedding transfer to unsupervised video object segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6526-6535. DOI: 10.1109/cvpr.2018.00683.
[6] LU X, WANG W, MA C, et al. See more, know more: Unsupervised video object segmentation with co-attention siamese networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 3623-3632. DOI: 10.1109/cvpr.2019.00374.
[7] 许欣. 无监督学习的视频多目标分割算法研究[D]. 徐州: 中国矿业大学, 2021. DOI: 10.27623/d.cnki.gzkyu.2021.001191. [8] 成华阳. 基于高效深度学习的实时无监督视频目标分割算法研究[D]. 成都: 电子科技大学, 2022. DOI: 10.27005/d.cnki.gdzku.2022.002787. [9] CAELLES S, MANINIS K K, PONT-TUSET J, et al. One-shot video object segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 221-230. DOI: 10.1109/mmsp.2019.8901723.
[10] TOKMAKOV P, ALAHARI K, SCHMID C. Learning video object segmentation with visual memory[C]//Proceedings of the IEEE International Conference on Computer Vision, 2017: 4481-4490. DOI: 10.1109/iccv.2017.480.
[11] CI H, WANG C, WANG Y. Video object segmentation by learning location-sensitive embeddings[C]//Proceedings of the European Conference on Computer Vision (ECCV), 2018: 501-516. DOI: 10.1007/978-3-030-01252-6_31.
[12] OH S W, LEE J Y, XU N, et al. Video object segmentation using space-time memory networks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision,2019: 9226-9235. DOI: 10.1109/iccv.2019.00932.
[13] 陈亚当, 赵翊冰, 吴恩华. 基于动态嵌入特征的鲁棒半监督视频目标分割[J]. 北京航空航天大学学报. DOI: 10.13700/j.bh.1001-5965.2023.0354. CHEN Y D, ZHAO Y B, WU E H. Robust semi-supervised video object segmentation with dynamic embedding[J]. Journal of Beijing University of Aeronautics and Astronautics. DOI:10.13700/j.bh.1001-5965.2023.0354. (in Chinese).
[14] 付利华, 赵宇, 姜涵煦, 等. 基于前景感知视觉注意的半监督视频目标分割[J]. 电子学报, 2022, 50(1): 195-206. DOI: 10.12263/DZXB.20201256. FU L H , ZHAO Y , JIANG H X , et al. Semi-Supervised video object segmentation based on foreground perception visual attention[J]. Acta Electonica Sinica, 2022, 50(1): 195-206. DOI:10.12263/DZXB.20201256. (in Chinese).
[15] 李兰. 基于深度学习的半监督视频目标分割方法研究[D]. 成都: 电子科技大学, 2023. DOI: 10.27005/d.cnki.gdzku.2023.001778. [16] OH S W, LEE J Y, XU N, et al. Fast user-guided video object segmentation by interaction-and-propagation networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 5247-5256. DOI: 10.1109/cvpr.2019.00539.
[17] HEO Y, JUN KOH Y, KIM C S. Interactive video object segmentation using global and local transfer modules[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 2020, Proceedings, Part XVII 16. Springer International Publishing, 2020: 297-313. DOI: 10.1007/978-3-030-58520-4_18.
[18] KHOREVA A, ROHRBACH A, SCHIELE B. Video object segmentation with referring expressions[C]//Computer Vision-ECCV Workshops. Munich, Germany, 2018, Proceedings Part Ⅳ. 2018: 7-12. DOI: 10.1007/978-3-030-11018-5_2.
[19] SEO S, LEE J Y, HAN B. Urvos: Unified referring video object segmentation network with a large-scale benchmark[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 2020, Proceedings, Part XV 16. Springer International Publishing, 2020: 208-223. DOI: 10.1007/978-3-030-58555-6_13.
[20] SIAM M, DORAISWAMY N, ORESHKIN B N, et al. Weakly supervised few-shot object segmentation using co-attention with visual and semantic embeddings[J]. Arxiv Preprint Arxiv: 2001.09540, 2020. DOI: 10.24963/ijcai.2020/120.
[21] 唐子淑, 刘杰, 别术林. 基于CV模型的CT图像分割研究[J]. CT理论与应用研究, 2014, 23(2): 193-202. TANG Z S, LIU J, BIE S L. Study of CT image segmentation based on CV model[J]. CT Theory and Applications, 2014, 23(2): 193-202. (in Chinese).
[22] 周茂, 曾凯, 杨奎, 等. 肺部CT图像分割方法研究[J]. CT理论与应用研究, 2018, 27(6): 683-691. DOI: 10.15953/j.1004-4140.2018.27.06.01. ZHOU M, CENG K, YANG K, et al. Research of lung segmentation based on CT image[J]. CT Theory and Applications, 2018, 27(6): 683-691. DOI: 10.15953/j.1004-4140.2018.27.06.01. (in Chinese).
[23] 邵叶秦, 杨新. 基于随机森林的CT前列腺分割[J]. CT理论与应用研究, 2015, 24(5): 647-655. DOI: 10.15953/j.1004-4140.2015.24.05.02. SHAO Y Q, YANG X. CT prostate segmentation based on random forest[J]. CT Theory and Applications, 2015, 24(5): 647-655. DOI: 10.15953/j.1004-4140.2015.24.05.02. (in Chinese).
[24] 杨昌俊, 杨新. 基于图割与快速水平集的腹部CT图像分割[J]. CT理论与应用研究, 2011, 20(3): 291-300. YANG C J, YANG X. Abdominal CT image segmentation based on graph cuts and fast level set[J]. CT Theory and Applications, 2011, 20(3): 291-300. (in Chinese).
[25] BELLO I, ZOPH B, VASWANI A, et al. Attention augmented convolutional networks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 3286-3295. DOI:10.1109/iccv.2019.00338. (in Chinese).
[26] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[J]. Advances in Neural Information Processing Systems, 2012, 25. DOI: 10.1145/3065386
[27] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. DOI: 10.1162/neco.1997.9.8.1735.
[28] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017, 30. DOI: 10.48550/arXiv.1706.03762.
[29] PARMAR N, VASWANI A, USZKOREIT J, et al. Image transformer[C]//International Conference on Machine Learning. PMLR, 2018: 4055-4064. DOI: 10.48550/arXiv.1802.05751.
[30] HOU R, CHANG H, MA B, et al. Cross attention network for few-shot classification[J]. Advances in Neural Information Processing Systems, 2019, 32. DOI: 10.48550/arXiv.1910.07677.
[31] DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. Arxiv Preprint Arxiv: 1810.04805, 2018. DOI: 10.18653/v1/N19-1423.
[32] BELLO I, ZOPH B, VASWANI A, et al. Attention augmented convolutional networks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 3286-3295. DOI: 10.1109/ICCV.2019.00338.
[33] ZHANG C, LIN G, LIU F, et al. Canet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 5217-5226. DOI: 10.1016/j.patcog.2021.108468.
[34] DENG J, DONG W, SOCHER R, et al. Imagenet: A large-scale hierarchical image database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009: 248-255. DOI: 10.1109/cvpr.2009.5206848.
[35] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 770-778. DOI: 10.1109/cvpr.2016.90
[36] CHEN H, WU H, ZHAO N, et al. Delving deep into many-to-many attention for few-shot video object segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 14040-14049. DOI: 10.1109/cvpr46437.2021.01382.
[37] ZHAO C, SHI S, HE Z, et al. Spatial-temporal V-Net for automatic segmentation and quantification of right ventricle on gated myocardial perfusion SPECT images[J]. Medical Physics, 2023, 50(12): 7415-7426. DOI: 10.1002/mp.16805.
[38] RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation[C]//Medical Image Computing and Computer-assisted Intervention-MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer International Publishing, 2015: 234-241. DOI: 10.1007/978-3-319-24574-4_28.



























































计量
- 文章访问数: 216
- HTML全文浏览量: 39
- PDF下载量: 29


