
Quality Improvement of CBCT-Synthesized CT Images Based on Improved CycleGAN
-
摘要:
目的:本研究提出一种基于改进型CycleGAN的无监督学习ViTD-CycleGAN,以从锥形束计算机断层扫描(CBCT)合成计算机断层扫描(CT)图像,旨在提高合成CT(sCT)图像质量和真实性。方法:ViTD-CycleGAN在生成器中引入了基于视觉转换器(ViT)的U-Net框架和深度卷积(DW),结合Transformer的自注意力机制,以提取并保留重要特征和细节信息。同时,引入梯度惩罚(GP)和像素级损失函数(PL),以增强模型训练的稳定性和图像一致性。结果:在头颈部和胸部数据集上的定量评价指标(MAE、PSNR、SSIM)均优于现有无监督学习方法。消融实验显示,DW对模型性能提升最为显著。视觉可视化分析进一步证实ViTD-CycleGAN生成的sCT图像具有更高的图像质量和真实性。结论:本研究提出的方法与其他无监督学习方法相比,可提高CBCT合成CT图像质量,具有一定的临床应用价值。
-
关键词:
- 锥形束计算机断层扫描 /
- 合成CT /
- CycleGAN /
- 图像质量改进 /
- 深度学习
Abstract:Objective: This study proposes an unsupervised learning model, ViTD-CycleGAN, based on an improved CycleGAN to synthesize computed tomography (CT) images from cone-beam computed tomography (CBCT) images. Our aim is to enhance the quality and realism of synthetic CT (sCT) images. Methods: ViTD-CycleGAN incorporates a U-Net framework based on a vision Transformer (ViT) and depth-wise convolution (DW) into its generator, where the self-attention mechanism of the Transformer is leveraged to extract and preserve crucial features and detailed information. Additionally, a gradient penalty and pixel-wise loss function are introduced to enhance the stability of the model training and image consistency. Results: Quantitative evaluation metrics (MAE, PSNR, and SSIM) for head and neck as well as chest datasets indicate the superior performance of the proposed model compared with existing unsupervised learning methods. Ablation experiments show that the DW significantly improved the model performance. Visual-display analysis confirms that the sCT images generated using the ViTD-CycleGAN exhibit higher image quality and realism. Conclusion: Compared with other unsupervised learning methods, the proposed method can improve the quality of CBCT-synthesized CT images and thus offer potential clinical application value.
-
图像引导放射治疗作为精准放射治疗的核心技术,在实时监测肿瘤和正常器官影像变化方面发挥着关键作用[1]。锥形束计算机断层扫描(cone-beam computed tomography,CBCT)作为其主要影像数据来源,因其轻量、开放式架构以及较低辐射暴露的优势,广泛应用于临床肿瘤放疗中的图像引导摆位和图像配准[2−3]。然而,CBCT图像软组织结构间对比度差,通常存在噪声和伪影[4−5]。为了进一步提高CBCT图像的质量和利用率,减少患者不必要的辐射,合成CT(synthetic computed tomography,sCT)技术应运而生。
在sCT的研究中,主要分为监督学习和无监督学习两种方法。监督学习依赖于配对数据,通过网络重建损失指导合成CT的生成。其中最具代表性的是全卷积网络(fully convolutional networks,FCN)和U-Net的变体[6−7]。例如,Zhang等[8]使用FCN进行MRI到CT的端到端非线性映射;Kida等[9]将2 D U-Net应用于骨盆区域的CBCT到CT合成;Li等[10]使用带残留块的改进U-Net结构在头颈部实现CBCT到CT的生成。然而,由于设置误差和器官运动等因素,很难获得完全配对的数据,因此基于监督学习的方法需要在网络训练前进行配对预处理,并且对图像配准算法的准确性要求很高。
相反,无监督学习不需要配对数据,依赖于网络自身结构或其他约束来生成合成CT图像[11]。典型的无监督模型如CycleGAN及其变体,在CBCT到CT的合成中取得了一定进展[12]。例如,Liu等[13]使用带注意门的3 D CycleGAN进行CBCT到CT的生成;Harms等[14]在生成器中添加残差块以实现端到端映射;Zeng等[15]提出了一种融合弱监督机制的hybrid GAN,在未配对数据有限的情况下进行MRI到CT的合成。此外,Torbunov等[16−17]还提出了梯度惩罚(gradient penalty,GP)和像素级损失函数(pixel-wise loss function,PL),旨在提高CycleGAN模型的稳定性和生成图像和源图像的一致性。尽管CycleGAN及其变体在CT合成领域取得了一些进展,CycleGAN及其变体在保留全局特征和生成图像的真实性方面仍然存在挑战,例如局部特征信息传递不足、模型坍塌和训练不稳定等问题[16]。
为了解决上述问题,本文提出一种新的无监督模型ViTD-CycleGAN,旨在提高sCT图像的质量和真实性。
1. 本文方法
原始CycleGAN如图1所示,生成器
$ G $ 旨在将输入图像$ x $ 转化合成为与目标域$ y $ 图像质量高度相似的合成图像$ G\left(x\right) $ 。鉴别器$ {D}_{y} $ 的目的是将目标域y中的真实图像与生成器$ G $ 合成的图像$ G\left(x\right) $ 区分开。CycleGAN的生成器只能保留和传递局部特征信息,无法进行全局特征的捕获,导致其生成的图像质量和真实性均较差。为了提高合成CT图像的质量,本研究对原始CycleGAN进行了以下改进。
(1)在生成器中引入基于视觉转换器(vision transformer,ViT)的U-Net框架,利用U-Net结构提取并保留重要的特征和细节信息,采用跳跃连接解决信息丢失问题;
(2)在前馈神经网络中引入深度卷积(depth-wise convolution,DW),结合Transformer的自注意力机制,使模型能够更好地理解图像的全局结构,并聚焦更多细节区域,使生成的图像更加清晰和真实;
(3)为了提高模型训练的稳定性,本文引入了GP,使得网络权重在输入微小变化时不会产生太大变化;
(4)为了提高生成图像和源图像的一致性,本文在生成器损失中添加了一个额外的PL,用以捕捉源图像和生成图像之间的差异。
1.1 ViTD-CycleGAN生成器结构
如图2所示,首先利用U-net结构提取并保留重要的组织特征和细节信息,采用跳跃连接解决信息丢失问题;然后利用Transformer的自注意力机制,在生成图像时自动关注图像不同位置的信息,更好地理解组织图像的全局结构;最后在前馈神经网络中进一步引入深度卷积,聚焦更多细节的区域,使得生成的图像更加清晰和真实。具体来说,U-net的编码路径通过四层卷积和下采样从输入中提取特征,将每一层提取到的特征通过跳跃连接传递到解码路径的相应层。在U-net的编码路径上,预处理层将图像转换为维数为
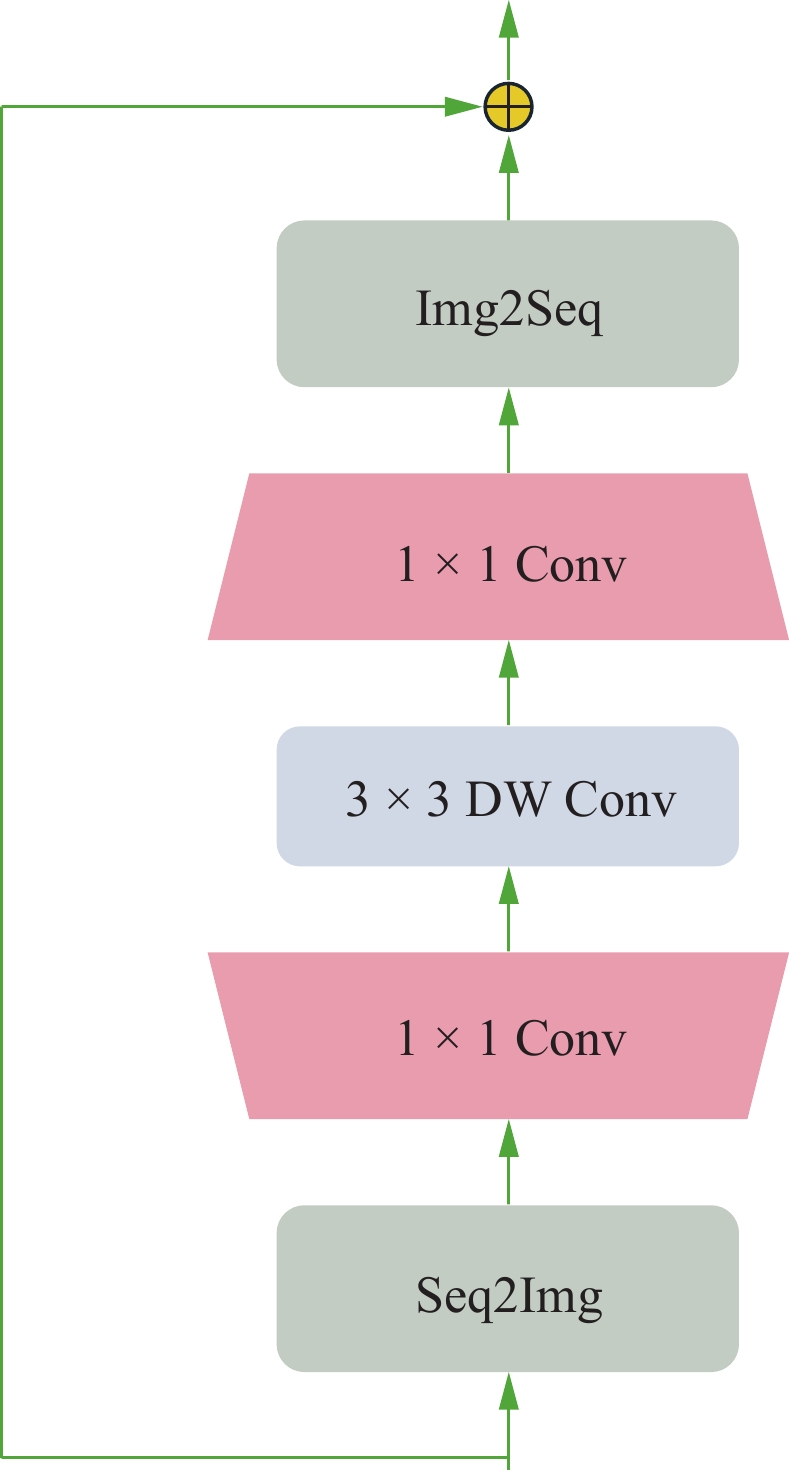
$ {(w}_{0},{h}_{0},{f}_{0}) $ 的张量,预处理后的张量在每个下采样块中宽度$ {w}_{0} $ 和高度$ {h}_{0} $ 减半,同时特征维数$ {f}_{0} $ 加倍。1.2 ViT模块
如图3所示,主要由Transformer编码器块堆栈组成,其输入尺寸为
$ \left(w,h,f\right)=\left(\mathrm{16,16,256}\right) $ 。ViT模块首先沿着空间维度展开编码形成序列,序列长度为$ w\times h $ ,序列中的每个标记都是长度为$ f $ 的向量。然后将标记与维度为$ {f}_{p} $ 的二维傅里叶位置编码嵌入连接,并将结果线性映射为维度$ {f}_{v} $ 作为Transformer编码器块输入。对于前馈神经网络,本文使用DW替代原始的全连接层,首先,将输入重塑为在二维网格上重新排列的特征图。然后,对特征图进行两次1×1卷积和一次深度卷积。之后,特征图被重塑为一个标记序列,并由网络转换层的自注意机制使用。最后为了提高收敛性,本文采用了Rezero正则化方案,并引入了一个可训练的标度参数
$ \alpha $ 来调制残差块的非平凡分支的幅度。堆栈的输出尺寸为$ \left(w,h,f\right) $ ,在本研究中使用12个Transformer编码器。其中,DW如图4所示,为了应对卷积运算,通过“Seq2 Img”和“Img2 Seq”添加序列和图像特征图之间的转换。1.3 梯度惩罚
为了提高训练稳定性,本文引入了通用的梯度惩罚GP[18]。损失函数如下:
$$ {\mathcal{L}}_{\mathrm{d}\mathrm{i}\mathrm{s}\mathrm{c},A}^{\mathrm{G}\mathrm{P}}={\mathcal{L}}_{\mathrm{d}\mathrm{i}\mathrm{s}\mathrm{c},A}+{\lambda }_{\mathrm{G}\mathrm{P}}\left[\frac{{\left(\parallel {\nabla }_{x}{\mathcal{D}}_{A}\left(x\right){\parallel }_{2}-\gamma \right)}^{2}}{{\gamma }^{2}}\right] 。 $$ (1) $ {\mathcal{L}}_{\mathrm{d}\mathrm{i}\mathrm{s}\mathrm{c},A}^{\mathrm{G}\mathrm{P}} $ 的定义如等式1所示,$ {\mathcal{L}}_{\mathrm{d}\mathrm{i}\mathrm{s}\mathrm{c},B}^{\mathrm{G}\mathrm{P}} $ 遵循相同的形式。其中,$ {\mathcal{L}}_{\mathrm{d}\mathrm{i}\mathrm{s}\mathrm{c},A}^{\mathrm{G}\mathrm{P}} $ 是带有梯度惩罚的判别器$ A $ 的损失函数,$ {\mathcal{L}}_{\mathrm{d}\mathrm{i}\mathrm{s}\mathrm{c},A} $ 是判别器$ A $ 的原始损失函数,$ {\lambda }_{\mathrm{G}\mathrm{P}} $ 是梯度惩罚的系数,$ \left[\displaystyle\frac{{\left(\parallel {\nabla }_{x}{\mathcal{D}}_{A}\left(x\right){\parallel }_{2}-\gamma \right)}^{2}}{{\gamma }^{2}}\right] $ 是梯度惩罚的具体表达形式,$ \parallel {\nabla }_{x}{\mathcal{D}}_{A}\left(x\right){\parallel }_{2} $ 是输入$ x $ 在判别器$ A $ 的输出$ {\mathcal{D}}_{A}\left(x\right) $ 上的梯度范数(L2范数),$ \gamma $ 是梯度惩罚的目标值。这种以$ \gamma $ 为中心的GP正则化可以提升模型训练的稳定性,并且对超参数选择的敏感性较低。1.4 像素级损失函数(PL)
为了增强生成图像与源图像的一致性,本文在生成器损失中引入了额外的PL[19]。这个损失项通过捕捉源图像与生成图像的缩小版本之间的
$ {L}_{1} $ 损失来实现。例如,对于域A的图像,其损失函数定义如下:$$ {\mathcal{L}}_{\mathrm{c}\mathrm{o}\mathrm{n}\mathrm{s}\mathrm{i}\mathrm{s}\mathrm{t},A}={\mathbb{E}}_{A}{L}_{1}\left(F\left({\mathrm{G}}_{A\to B}\right(a\left)\right),F\left(a\right)\right) \text{,} $$ (2) 其中,
$ {\mathcal{L}}_{\mathrm{c}\mathrm{o}\mathrm{n}\mathrm{s}\mathrm{i}\mathrm{s}\mathrm{t},A} $ 是用于域$ A $ 的一致性损失函数,$ {\mathbb{E}}_{A} $ 是域$ A $ 中所有图像的期望,$ {L}_{1} $ 是绝对差值损失,$ F $ 是缩小至32×32像素的大小调整运算符(低通滤波器),$ F\left({\mathrm{G}}_{A\to B}\right(a\left)\right)\mathrm{和}F\left(a\right) $ 这两个部分表示经过$ F $ 操作后的生成图像和源图像,$ {\mathrm{G}}_{A\to B}\left(a\right) $ 是生成器$ \mathrm{G} $ 的输出。将此项添加到生成器损失(1)中,两个域的幅度均为$ {\mathcal{L}}_{\mathrm{c}\mathrm{o}\mathrm{n}\mathrm{s}\mathrm{i}\mathrm{s}\mathrm{t}} $ 。这种通过增加像素级损失函数,确保生成图像在低分辨率下与源图像的一致性,从而提高生成器的效果。2. 实验介绍
2.1 数据集介绍
2.1.1 头颈部数据集
回顾性收集2021年10月1日至2023年12月1日期间接受容积调强放射治疗(volumetric modulated arc therapy,VMAT)的鼻咽癌和下咽癌患者的扫描数据。数据集包括
5400 幅CT图像与5400 幅CBCT图像。CT图像通过GE Discovery模拟定位机获得,参数如下:管电压120 kV,曝光量250 mAs,层厚为2.75 mm,矩阵大小为512×512,像素大小为0.625×0.625 mm2。CBCT图像通过Elekta XVI锥形束CT图像引导系统获得,参数为旋转200度,管电压120 kVp,管电流10 mA,曝光时间为10 ms,F0 S20准直器,矩阵大小为384×384,像素大小为1×1 mm2。按照8∶2的比例随机划分训练集和测试集。2.1.2 胸部数据集
回顾性收集2021年10月1日至2024年3月1日期间接受VMAT的肺癌和食管癌患者的扫描数据。数据集包括
4200 幅CT图像与4200 幅CBCT图像。CT图像通过GE Discovery模拟定位机获得,参数为管电压120 kV,曝光量250 mAs,切片厚度为5 mm,矩阵大小为512×512,像素大小为0.625×0.625 mm2。CBCT图像通过Elekta XVI锥形束CT图像引导系统获得,参数为旋转360度,管电压100 kVp,管电流10 mA,曝光时间10 ms,F0 M10准直器,矩阵大小为410×410,像素大小为1×1 mm2。同样按照8∶2的比例随机划分训练集和测试集。2.2 图像预处理
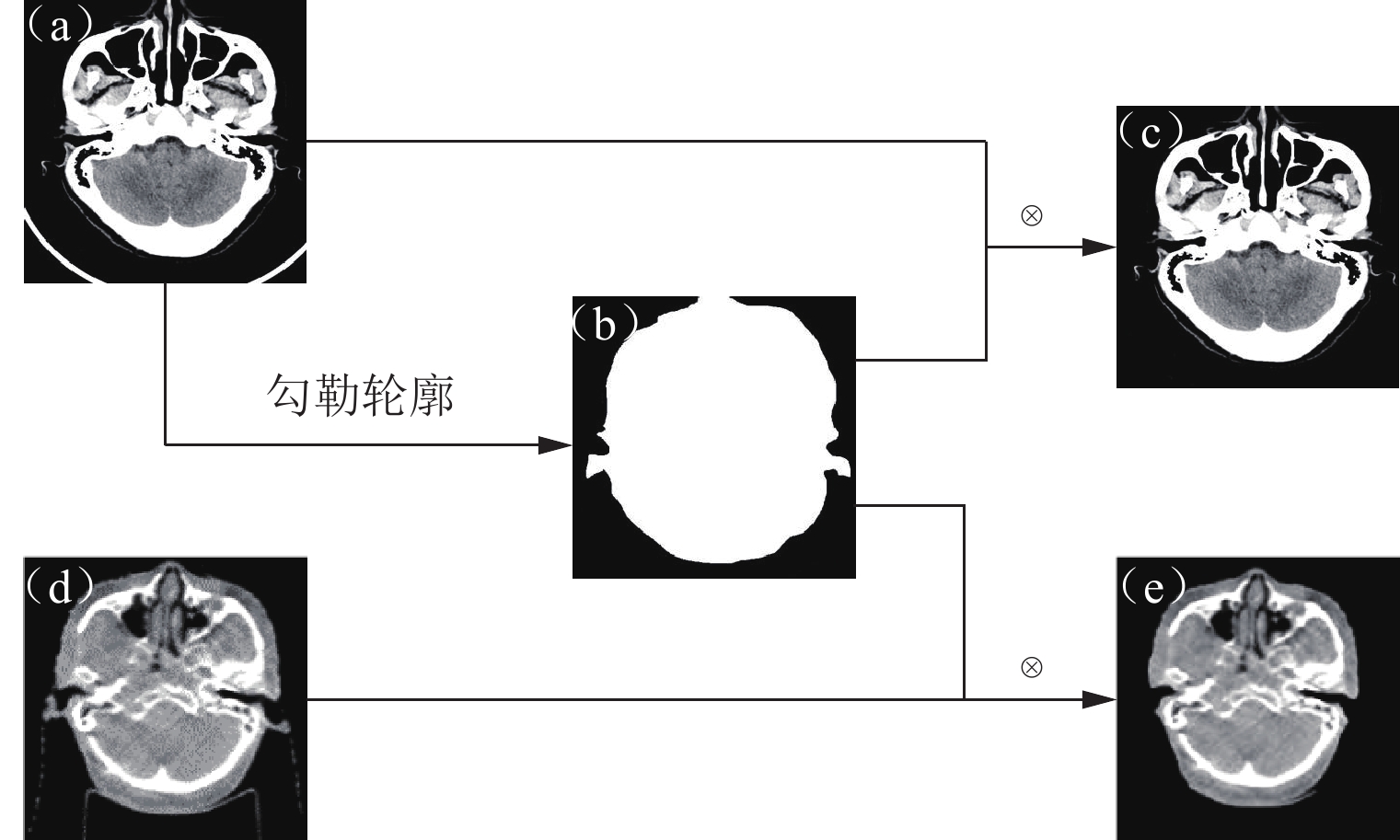
在扫描过程中,非组织结构如治疗床、固定装置和口罩等也会出现在CBCT和CT图像中,这不仅会降低模型的训练速度,还会影响合成图像的质量。因此,在模型训练前,必须进行图像预处理,特别是非组织结构的去除,流程如图5所示。
![]() 图 5 去除非组织结构流程图注:(a)原始CT图像,(b)医生手动勾勒的CT轮廓,(c)去除非组织结构的CT图像,(d)原始CBCT图像,(e)去除非组织结构的CBCT图像。首先,医生手动勾勒的CT轮廓作为掩码(mask),将掩码与CT图像相乘以获得去除非组织结构的图像,再将掩码与CBCT图像相乘以获得去除非组织结构的CBCT图像。Figure 5. Flowchart of non-tissue structure removal
图 5 去除非组织结构流程图注:(a)原始CT图像,(b)医生手动勾勒的CT轮廓,(c)去除非组织结构的CT图像,(d)原始CBCT图像,(e)去除非组织结构的CBCT图像。首先,医生手动勾勒的CT轮廓作为掩码(mask),将掩码与CT图像相乘以获得去除非组织结构的图像,再将掩码与CBCT图像相乘以获得去除非组织结构的CBCT图像。Figure 5. Flowchart of non-tissue structure removal此外,CBCT和CT在图像采集设备、临床操作和扫描位置等方面存在差异,即使是同一患者,CBCT与CT也难以完全配对。由于在数据采集过程中器官位置相对固定,组织流动性较低,本文使用开源高级规范化工具(advanced normalization tools,ANTs)进行仿射配准,以对齐每一对CBCT与CT图像,用于模型测试[20]。
2.3 网络预训练
在实验中,所有图像都被归一化到[-1,1],并且大小调整为256×256。本文对生成器进行五次训练,然后对鉴别器进行一次训练。其参数设置为Epoch=200,Batch size=5。其他比较方法是基于作者提供的代码和细节实现的,具有与本文相同的超参数设置。本研究所有算法在搭载了4块NVIDIA Tesla V100的Linux系统上使用Python 3.6和TensorFlow 1.14实现。
2.4 图像评价指标
为评估CycleGAN、DualGAN、AttentionGAN、ADCycleGAN和ViTD-CycleGAN生成的sCT图像与真实CT图像之间的相似度,本研究引入了平均绝对误差(mean absolute error,MAE)、峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity index,ssim)等定量的评价指标[21]。
MAE的计算公式如下:
$$ MAE=\frac{1}{n}\sum _{i=1}^{n}\Big|{x}_{i}-{G}_{CBCT\to CT}\left({y}_{i}\right)\Big| \text{,} $$ (3) 其中,
$ n $ 为测试样本数量,$ x $ 和$ y $ 分别为真实(Real)CT和真实CBCT图像。真实CBCT经过CBCT生成器$ {G}_{CBCT\to CT} $ 之后,生成伪(Fake)CT图像,并与真实CT图像计算绝对误差。MAE值越小,表示生成的sCT图像与真实CT的差异越小,图像越逼真。PSNR的计算公式如下:
$$ PSNR=20lo{g}_{10}\frac{MA{X}_{rCT}}{MSE} \text{,} $$ (4) 其中,
$ MA{X}_{rCT} $ 为sCT中的最大像素值,MSE为均方误差。PSNR值越高,表示伪CT图像与真实CT图像的相似度越高。SSIM的计算公式如下:
$$ SSIM=\frac{(2{\mu }_{x}{\mu }_{y}+{c}_{1})(2{\sigma }_{xy}+{c}_{2})}{({\mu }_{x}^{2}+{\mu }_{y}^{2}+{c}_{1})({\sigma }_{x}^{2}+{\sigma }_{y}^{2}+{c}_{2})} \text{,} $$ (5) 其中,
$ x $ 和$ y $ 分别为真实CT和真实CBCT图像经过生成器$ {G}_{CBCT\to CT} $ 之后生成的伪CT,$ {\mu }_{x} $ 和$ {\mu }_{y} $ 为$ x $ 和$ y $ 的平均值,$ {\sigma }_{x} $ 和$ {\sigma }_{y} $ 为$ x $ 和$ y $ 的方差,$ {\sigma }_{xy} $ 为$ x $ 和$ y $ 的协方差,而$ {c}_{1} $ 和$ {c}_{2} $ 则是用来维持稳定的两个常数。SSIM值的范围为[−1,1],值越大表明两张图像的相似度越高。2.5 消融实验
此外,通过消融实验进一步验证了各模块对整体性能的提升效果。以CycleGAN-ViT作为基线模型,逐步引入DW、GP和PL模块,观察各次实验的MAE、PSNR和SSIM值变化,从而评估各模块的贡献[22]。
3. 实验结果
3.1 图像评价结果
表1和表2展示了本文方法与其他对比算法在头颈部和胸部数据集上的定量结果。在头颈部数据集上,ViTD-CycleGAN在MAE、PSNR和SSIM 3个评估指标上均优于CycleGAN及其变体。这主要得益于引入了改进型ViT的U-net框架,该框架有效提取并保留了重要特征和细节信息,自动关注图像的不同位置,更好地理解全局结构,并聚焦更多细节区域,使生成的图像更加清晰和真实。同样,在胸部数据集上的实验结果也显示,ViTD-CycleGAN在所有指标上均表现出显著优势。
表 1 不同网络在头颈部数据集上的指标比较Table 1. Comparison of metrics of different networks on head and neck dataset网络 MAE PSNR SSIM CycleGAN 15.24 29.1025 0.9713 DualGAN 18.63 28.5974 0.9627 AttentionGAN 25.71 27.1345 0.9518 ADCycleGAN 13.53 30.1609 0.9763 ViTD-CycleGAN 10.96 31.8561 0.9832 表 2 不同网络在胸部数据集上的指标比较Table 2. Comparison of metrics for different networks on chest dataset网络 MAE PSNR SSIM CycleGAN 20.82 27.6613 0.9613 DualGAN 27.54 25.3516 0.9427 AttentionGAN 23.23 26.1269 0.9524 ADCycleGAN 15.14 28.4558 0.9647 ViTD-CycleGAN 13.41 29.1315 0.9721 3.2 消融实验结果
头颈部数据集上的实验结果如表3所示,胸部数据集上的实验结果如表4所示。实验结果表明,每个模块都对整体性能有所贡献。通过对比MAE、PSNR和SSIM评价指标,我们发现DW在提升模型性能方面要优于GP和PL,其效果更加显著。
表 3 头颈部数据集消融定量结果Table 3. Quantitative results of ablation for head and neck dataset消融实验 MAE PSNR SSIM CycleGAN-ViT 14.92 29.2558 0.9728 CycleGAN-ViT-DW 13.17 29.8635 0.9765 CycleGAN-ViT-GP 13.52 29.3921 0.9757 CycleGAN-ViT-PL 14.67 29.3332 0.9749 CycleGAN-ViT-DW-GP 11.79 31.4937 0.9827 CycleGAN-ViT-DW-PL 12.66 30.3532 0.9784 CycleGAN-ViT-GP-PL 12.35 31.0169 0.9809 ViTD-CycleGAN 10.98 31.8565 0.9836 表 4 胸部数据集消融定量结果Table 4. Quantitative results of ablation for chest dataset消融实验 MAE PSNR SSIM CycleGAN-ViT 16.89 27.9829 0.9632 CycleGAN-ViT-DW 15.07 28.5627 0.9687 CycleGAN-ViT-GP 15.38 28.3597 0.9663 CycleGAN-ViT-PL 16.15 28.0131 0.9643 CycleGAN-ViT-DW-GP 13.79 28.9657 0.9704 CycleGAN-ViT-DW-PL 14.37 28.6819 0.9697 CycleGAN-ViT-GP-PL 14.02 28.7719 0.9706 ViTD-CycleGAN 13.41 29.1323 0.9724 3.3 视觉可视化分析
在对sCT图像进行定量评估的基础上,本研究通过多角度的视觉分析,对比不同模型生成的结果,以验证本文方法的优势。如图6和图7所示,ViTD-CycleGAN生成的图像不仅噪声较低,且细节更加清晰,与真实CT图像的相似度更高。具体分析如下:
头颈部数据集分析:
图6第1行(椎体区域,绿色箭头):ViTD-CycleGAN生成的sCT图像与真实CT的相似度最高,而ADCycleGAN和RegGAN的表现也较为接近。相比之下,CycleGAN、DualGAN和AttentionGAN在椎体区域显示出明显的形态差异,生成的图像细节模糊,且噪声明显。
图6第2行(鼻咽部,蓝色箭头):尽管ADCycleGAN、RegGAN、CycleGAN和DualGAN生成的结果在形态上相对相似,但与真实CT相比,边界依然模糊,且细节信息有所丢失。相较而言,ViTD-CycleGAN生成的sCT细节清晰,与真实CT的差距最小,而AttentionGAN表现最差。
图6第3行(垂体区域,黄色箭头):ViTD-CycleGAN生成的图像与真实CT最为接近,边界清晰且形态差异较小。ADCycleGAN、RegGAN和CycleGAN生成的图像细节有所丢失,特别是在眼部区域失真较为明显,而DualGAN和AttentionGAN的整体表现较差。
图6第4行(眼部区域,橙色箭头):虽然ADCycleGAN、RegGAN和CycleGAN在眼部区域与真实CT的差异不大,但在脑组织区域存在严重失真。相较之下,ViTD-CycleGAN生成的sCT表现最佳,DualGAN和AttentionGAN的表现较为逊色。
胸部数据集分析:
图7第1行(支气管分叉区域,绿色箭头):尽管ADCycleGAN、RegGAN和CycleGAN在支气管区域生成的图像与真实CT的差异较小,细节丢失依然明显。ViTD-CycleGAN生成的图像表现最佳,而DualGAN和AttentionGAN的表现相对较差。
图7第2行(椎体区域,蓝色箭头):ADCycleGAN和RegGAN在形态上与真实CT差异较小,CycleGAN、DualGAN和AttentionGAN差异较大。ViTD-CycleGAN生成的sCT与真实CT的接近度最高。
图7第3行(肺部肿瘤区域,黄色虚线圆圈):虽然ADCycleGAN和RegGAN在形态上与真实CT差异不大,但心脏和椎体区域的信息有所缺失。ViTD-CycleGAN生成的sCT与真实CT的相似度最高,CycleGAN、DualGAN和AttentionGAN的表现则相对较差。
图7第4行(肺部肿瘤区域,橙色虚线圆圈):ADCycleGAN和RegGAN生成的肺部图像在形态上与真实CT相似,但心脏区域的信息有所缺失。ViTD-CycleGAN生成的sCT更为清晰,失真较少,CycleGAN、DualGAN和AttentionGAN的表现较差。
图8展示了CBCT、ViTD-CycleGAN生成的sCT与真实CT之间的差异图。可以看出,ViTD-CycleGAN生成的sCT与真实CT的差异最小,进一步证明了本文方法的有效性。
![]() 图 8 CBCT、本文方法和真实CT之间的差异图Figure 8. Plot of differences among CBCT, methods used in this study, and actual CT
图 8 CBCT、本文方法和真实CT之间的差异图Figure 8. Plot of differences among CBCT, methods used in this study, and actual CT4. 讨论
本研究提出了一种基于CycleGAN的无监督学习模型ViTD-CycleGAN,用于CBCT合成sCT。实验结果表明其在MAE、PSNR和SSIM等关键指标上优于传统方法。我们将结合国内外最新文献,详细分析本研究方法的优势、与现有研究的比较、临床应用意义及未来研究方向。
4.1 方法优势及改进点
传统的CycleGAN在处理医学影像时,难以同时兼顾细节和全局特征,这导致生成的图像质量不够理想。而本研究通过引入ViT的U-net框架,不仅保留了更多的细节信息,还有效捕捉了图像的全局特征,从而显著提升了生成图像的质量。此外,DW的引入进一步减少了模型参数量并提升了计算效率,使得生成的图像在细节上更加精细[23]。
为了进一步提高模型的稳定性及生成图像的质量,本文在训练过程中还引入了GP和PL。GP有助于提高模型的训练稳定性,减少生成过程中的不稳定性,而PL则确保了生成图像与真实图像在像素级别的一致性[16−17]。
4.2 与现有研究的比较
与传统的CycleGAN模型相比,本研究的改进型CycleGAN在多个方面表现出显著优势。传统的CycleGAN在处理CBCT图像时,生成的CT图像质量较差,常见的伪影和噪声问题没有得到有效解决。而本研究通过引入ViT的U-net框架,显著改善了这些问题[24]。此外,与Liu等[13]使用深度注意力CycleGAN生成高质量的sCT图像的研究相比,本研究的ViTD-CycleGAN在细节保留和全局结构捕捉方面表现更为出色。
4.3 临床应用及意义
本研究提出的方法在头颈部和胸部肿瘤患者的CBCT图像合成CT方面取得了良好的效果,可以提高CBCT图像的利用率,减少患者不必要的辐射。同时,ViTD-CycleGAN生成的sCT图像在准确度和一致性方面表现出色,也为放射治疗的精确规划提供了保证。
4.4 局限性与未来研究方向
尽管本研究中的ViTD-CycleGAN在CBCT合成CT的应用中表现出良好的效果,但仍存在一些局限性和改进空间。首先,本研究主要针对头颈部和胸部肿瘤患者,尚未对其他部位的适用性进行充分验证。在未来研究中,我们计划扩展数据集,进一步验证模型的普适性和稳定性。其次,尽管引入了ViT等模块提升了网络性能,但这也显著增加了计算资源的消耗和训练时间的延长。未来研究中,我们将致力于优化网络结构,降低计算资源的需求,特别是通过探索4 bit量化技术等轻量化部署方案,提升模型在实际应用中的可行性[25];最后,本研究属于单中心研究,不同扫描参数、不同型号扫描设备可能会影响实验结果。在未来研究中,我们将多中心验证本研究的泛化能力。
综上所述,本文提出了一种改进型CycleGAN模型ViTD-CycleGAN,用于从CBCT合成CT图像。通过引入ViT的U-net框架、DW、GP和PL,显著提升了合成CT图像的质量。在头颈部和胸部数据集上的实验结果表明,ViTD-CycleGAN在各项指标上均优于现有方法,具有重要的临床应用价值。
-
![]()
图 5 去除非组织结构流程图
注:(a)原始CT图像,(b)医生手动勾勒的CT轮廓,(c)去除非组织结构的CT图像,(d)原始CBCT图像,(e)去除非组织结构的CBCT图像。首先,医生手动勾勒的CT轮廓作为掩码(mask),将掩码与CT图像相乘以获得去除非组织结构的图像,再将掩码与CBCT图像相乘以获得去除非组织结构的CBCT图像。
Figure 5. Flowchart of non-tissue structure removal
![]()
图 8 CBCT、本文方法和真实CT之间的差异图
Figure 8. Plot of differences among CBCT, methods used in this study, and actual CT
表 1 不同网络在头颈部数据集上的指标比较
Table 1 Comparison of metrics of different networks on head and neck dataset
网络 MAE PSNR SSIM CycleGAN 15.24 29.1025 0.9713 DualGAN 18.63 28.5974 0.9627 AttentionGAN 25.71 27.1345 0.9518 ADCycleGAN 13.53 30.1609 0.9763 ViTD-CycleGAN 10.96 31.8561 0.9832  下载: 导出CSV
下载: 导出CSV
表 2 不同网络在胸部数据集上的指标比较
Table 2 Comparison of metrics for different networks on chest dataset
网络 MAE PSNR SSIM CycleGAN 20.82 27.6613 0.9613 DualGAN 27.54 25.3516 0.9427 AttentionGAN 23.23 26.1269 0.9524 ADCycleGAN 15.14 28.4558 0.9647 ViTD-CycleGAN 13.41 29.1315 0.9721
下载: 导出CSV
表 3 头颈部数据集消融定量结果
Table 3 Quantitative results of ablation for head and neck dataset
消融实验 MAE PSNR SSIM CycleGAN-ViT 14.92 29.2558 0.9728 CycleGAN-ViT-DW 13.17 29.8635 0.9765 CycleGAN-ViT-GP 13.52 29.3921 0.9757 CycleGAN-ViT-PL 14.67 29.3332 0.9749 CycleGAN-ViT-DW-GP 11.79 31.4937 0.9827 CycleGAN-ViT-DW-PL 12.66 30.3532 0.9784 CycleGAN-ViT-GP-PL 12.35 31.0169 0.9809 ViTD-CycleGAN 10.98 31.8565 0.9836
下载: 导出CSV
表 4 胸部数据集消融定量结果
Table 4 Quantitative results of ablation for chest dataset
消融实验 MAE PSNR SSIM CycleGAN-ViT 16.89 27.9829 0.9632 CycleGAN-ViT-DW 15.07 28.5627 0.9687 CycleGAN-ViT-GP 15.38 28.3597 0.9663 CycleGAN-ViT-PL 16.15 28.0131 0.9643 CycleGAN-ViT-DW-GP 13.79 28.9657 0.9704 CycleGAN-ViT-DW-PL 14.37 28.6819 0.9697 CycleGAN-ViT-GP-PL 14.02 28.7719 0.9706 ViTD-CycleGAN 13.41 29.1323 0.9724
下载: 导出CSV
-
[1] JAFFRAY D A. Image-guided radiotherapy: From current concept to future perspectives[J]. Nature Reviews Clinical Oncology, 2012, 9(12): 688-699. DOI: 10.1038/nrclinonc.2012.194.
[2] 张帅楠, 田龙, 赵鑫. 前列腺癌图像引导放疗中锥形束CT为合成CT提供质量保证的可行性研究[J]. 医疗卫生装备, 2023, 44(8): 50-54. DOI: 10.19745/j.1003-8868.2023161. ZHANG S N, TIAN L, ZHAO X. Feasibility study of cone-beam CT for quality assurance of synthetic CT in image-guided radiotherapy for prostate cancer[J]. Chinese Medical Equipment Journal, 2023, 44(8): 50-54. DOI: 10.19745/j.1003-8868.2023161.
[3] LIU Y, LEI Y, WANG T, et al. MRI-based treatment planning for liver stereotactic body radiotherapy: Validation of a deep learning-based synthetic CT generation method[J]. The British Journal of Radiology, 2019, 92(1100): 20190067. DOI: 10.1259/bjr.20190067.
[4] 冉雪琪, 李建锋, 曹绍艾. 探讨低剂量口腔CBCT检查中耳鼻喉相关组织的表现[J]. CT理论与应用研究, 2022, 31(3): 392-398. DOI: 10.15953/j.ctta.2021.035. RAN X Q, LI J F, CAO S A. Analysis of the manifestations of ENT in low-dose oral CBCT examination[J]. CT Theory and Applications, 2022, 31(3): 392-398. DOI: 10.15953/j.ctta.2021.035.
[5] HUNTER A K, MCDAVID W D. Characterization and correction of cupping effect artifacts in cone beam CT. Dentomaxillofacial Radiol, 2012, 41(3): 217. DOI: 10.1259/dmfr/19015946.
[6] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440. DOI: 10.1109/CVPR.2015.7298965.
[7] CHEN S, QIN A, ZHOU D, et al. U-net-generated synthetic CT images for magnetic resonance imaging-only prostate intensity-modulated radiation therapy treatment planning[J]. Medical Physics, 2018, 45(12): 5659-5665. DOI: 10.1002/mp.13247.
[8] ZHANG S, HUANG W, WANG H. Lesion detection of computed tomography and magnetic resonance imaging image based on fully convolutional networks[J]. Journal of Medical Imaging and Health Informatics, 2018, 8(9): 1819-1825. DOI: 10.1166/jmihi.2018.2565.
[9] KIDA S, NAKAMOTO T, NAKANO M, et al. Cone beam computed tomography image quality improvement using a deep convolutional neural network[J]. Cureus, 2018, 10(4). DOI: 10.7759/cureus.2548.
[10] LI Y, ZHU J, LIU Z, et al. A preliminary study of using a deep convolution neural network to generate synthesized CT images based on CBCT for adaptive radiotherapy of nasopharyngeal carcinoma[J]. Physics in Medicine & Biology, 2019, 64(14): 145010. DOI: 10.1088/1361-6560/ab2770.
[11] JAMES G, WITTEN D, HASTIE T, et al. Unsupervised learning[M]//An Introduction to Statistical Learning: with Applications in Python. Cham: Springer International Publishing, 2023: 503-556. DOI: 10.1007/978-3-031-38747-0_12.
[12] SANDFORT V, YAN K, PICKHARDT P J, et al. Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks[J]. Scientific reports, 2019, 9(1): 16884. DOI: 10.1038/s41598-019-52737-x.
[13] LIU Y, LEI Y, WANG T, et al. CBCT-based synthetic CT generation using deep-attention CycleGAN for pancreatic adaptive radiotherapy[J]. Medical Physics, 2020, 47(6): 2472-2483. DOI: 10.1002/mp.14121.
[14] HARMS J, LEI Y, WANG T, et al. Paired cycle-GAN-based image correction for quantitative cone-beam computed tomography[J]. Medical Physics, 2019, 46(9): 3998-4009. DOI: 10.1002/mp.13656.
[15] ZENG G, ZHENG G. Hybrid generative adversarial networks for deep MR to CT synthesis using unpaired data[C]//Medical Image Computing and Computer Assisted Intervention-MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13-17, 2019, Proceedings, Part IV 22. Springer International Publishing, 2019: 759-767. DOI: 10.1007/978-3-030-32251-9_83.
[16] TORBUNOV D, HUANG Y, YU H, et al. Uvcgan: Unet vision transformer cycle-consistent gan for unpaired image-to-image translation[C]//Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2023: 702-712. DOI: 10.48550/arXiv.2203.02557.
[17] TORBUNOV D, HUANG Y, TSENG H H, et al. UVCGAN v2: An Improved Cycle-consistent GAN for Unpaired Image-to-Image Translation[J]. arXiv preprint arXiv: 2303.16280, 2023. DOI: 10.48550/arXiv.2303.16280.
[18] ZHENG M, LI T, ZHU R, et al. Conditional Wasserstein generative adversarial network-gradient penalty-based approach to alleviating imbalanced data classification[J]. Information Sciences, 2020, 512: 1009-1023. DOI: 10.1016/j.ins.2019.10.014.
[19] YU Z, LI X, SHI J, et al. Revisiting pixel-wise supervision for face anti-spoofing[J]. IEEE Transactions on Biometrics, Behavior, and Identity Science, 2021, 3(3): 285-295. DOI: 10.1109/TBIOM.2021.3065526.
[20] AVANTS B B, TUSTISON N J, SONG G, et al. A reproducible evaluation of ANTs similarity metric performance in brain image registration[J]. Neuroimage, 2011, 54(3): 2033-2044. DOI: 10.1016/j.neuroimage.2010.09.025.
[21] MOLLINK J, VAN BAARSEN KM, DEDEREN PJ, et al. Dentatorubrothalamic tract localization with postmortem MR diffusion tractography compared to histological 3D reconstruction[J]. Brain Struct Funct, 2016, 221(7): 3487-3501. DOI: 10.1007/s00429-015-1115-7.
[22] 樊雪林, 文昱齐, 乔志伟. 基于 Transformer 增强型 U-net的CT图像稀疏重建与伪影抑制[J]. CT理论与应用研究(中英文), 2024, 33(1): 1-12. DOI: 10.15953/j.ctta.2023.183. FAN X L, WEN Y Q, QIAO Z W. Sparse reconstruction of computed tomography images with transformer enhanced U-net[J]. CT Theory and Applications, 2024, 33(1): 1-12. DOI: 10.15953/j.ctta.2023.183.
[23] JIQING C, DEPENG W, TENG L, et al. All-weather road drivable area segmentation method based on CycleGAN[J]. The Visual Computer, 2023, 39(10): 5135-5151. DOI: 10.1007/s00371-022-02650-8.
[24] MAO X, QI G, CHEN Y, et al. Towards robust vision transformer[C]//Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. 2022: 12042-12051. DOI: 10.48550/arXiv.2105.07926.
[25] BANNER R, NAHSHAN Y, SOUDRY D. Post training 4-bit quantization of convolutional networks for rapid-deployment[J]. Advances in Neural Information Processing Systems, 2019, 32.
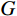
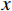
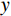
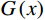
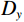
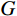
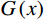
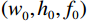
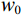
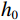
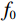

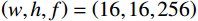

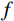
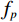
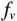

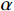
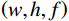
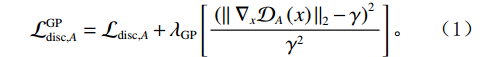
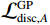
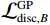
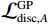
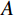
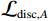
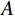
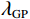
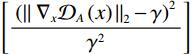
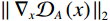
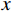
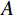
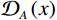
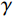
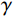
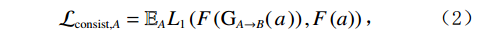

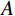
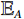
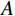
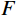
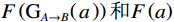

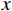
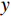
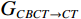
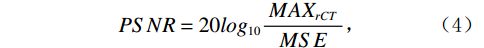
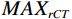
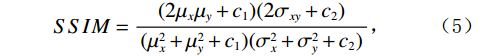
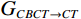
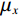
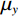
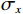
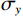
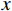
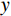
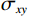
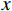
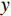
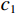




计量
- 文章访问数: 126
- HTML全文浏览量: 12
- PDF下载量: 29


