
Enhanced Restormer for Low-Dose CT Image Reconstruction Based on Multi-Attention Fusion
-
摘要:
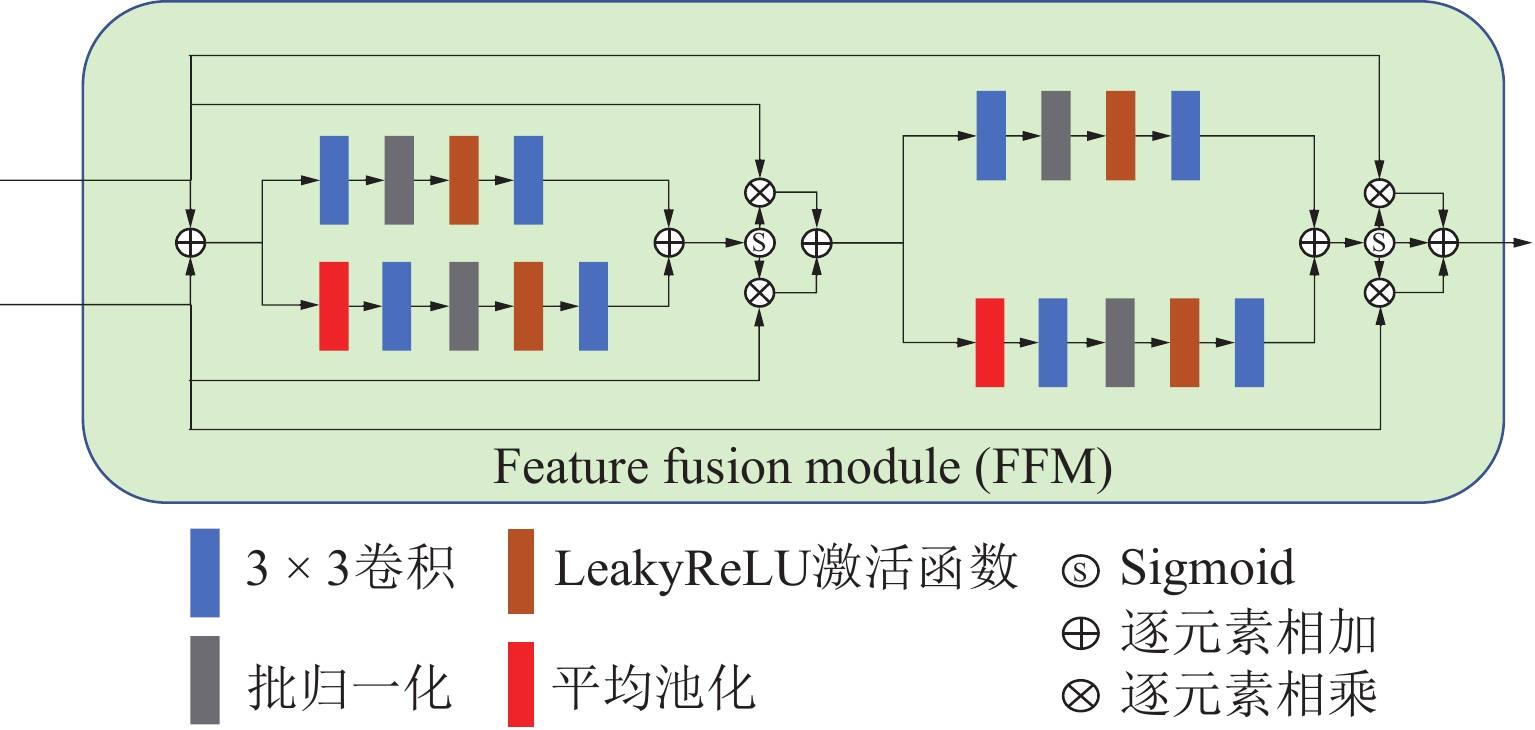
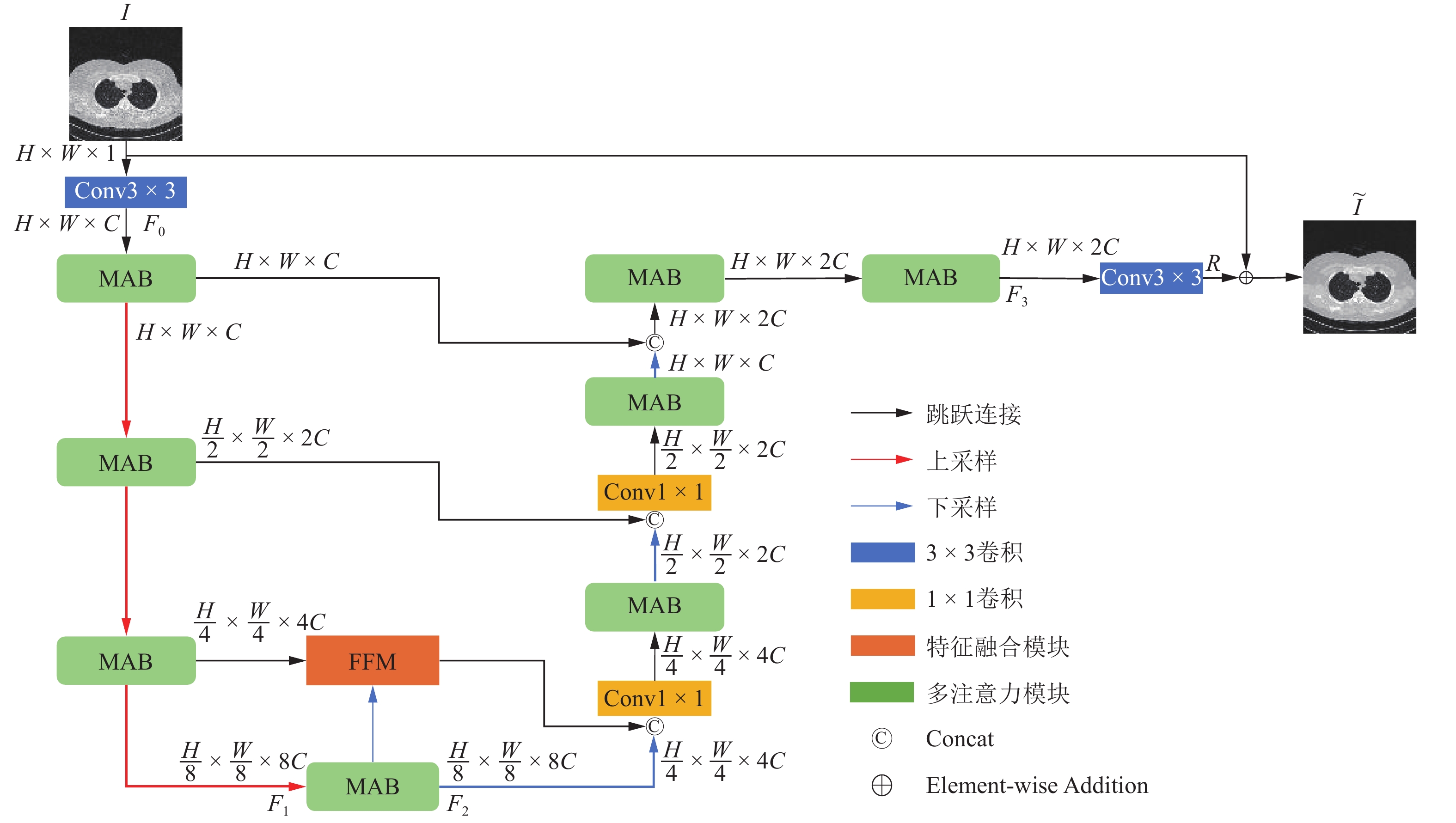
计算机断层成像(CT)技术在医学诊断中起着至关重要的作用。在CT图像重建中保持投影角度数量不变的情况下,降低每个投影角度的辐射剂量,是一种实现低剂量CT的有效方法。这会使得重建出的CT图像中含有较大的噪声,影响后续的图像分析和研究。针对上述问题,提出一种融合多注意力机制和特征融合机制的增强的Restormer网络(ERestormer)用于低剂量CT图像去噪。该网络融合了通道注意力、感受野注意力和多头转置注意力以增强网络对重要信息的关注能力,进而提高网络的特征学习能力。另外,本网络引入特征融合机制来增强编码器和解码器之间的特征复用。实验结果证明,与DNCNN、RED-CNN、UNet、Uformer和Restormer 5种经典的网络相比,所提出的网络具有更好的去噪性能和保留图像细节信息的能力。
Abstract:Computed Tomography (CT) technology plays a crucial role in medical diagnosis. Reducing the radiation dose per projection angle while maintaining a constant number of projection angles is an effective approach to achieving low-dose CT. However, this reduction often introduces significant noise into the reconstructed CT images, adversely affecting subsequent image analysis and research. To address this issue, we propose the Enhanced Restormer for Low-Dose CT Image Reconstruction Based on Multi-Attention Fusion (ERestormer) for low-dose CT image denoising. The network integrates channel attention, receptive field attention, and multi-head transposed attention to enhance the model’s ability to focus on critical information, thereby improving its feature learning capacity. Furthermore, a feature fusion mechanism is introduced to strengthen feature reuse between the encoder and decoder. Experimental results show that the proposed network achieves superior denoising performance and enhanced preservation of image detail when compared to five classical networks: DNCNN, RED-CNN, UNet, Uformer, and Restormer.
-
Keywords:
- computed tomography /
- low-dose CT /
- channel attention /
- receptive field attention /
- feature fusion
-
-
![]()
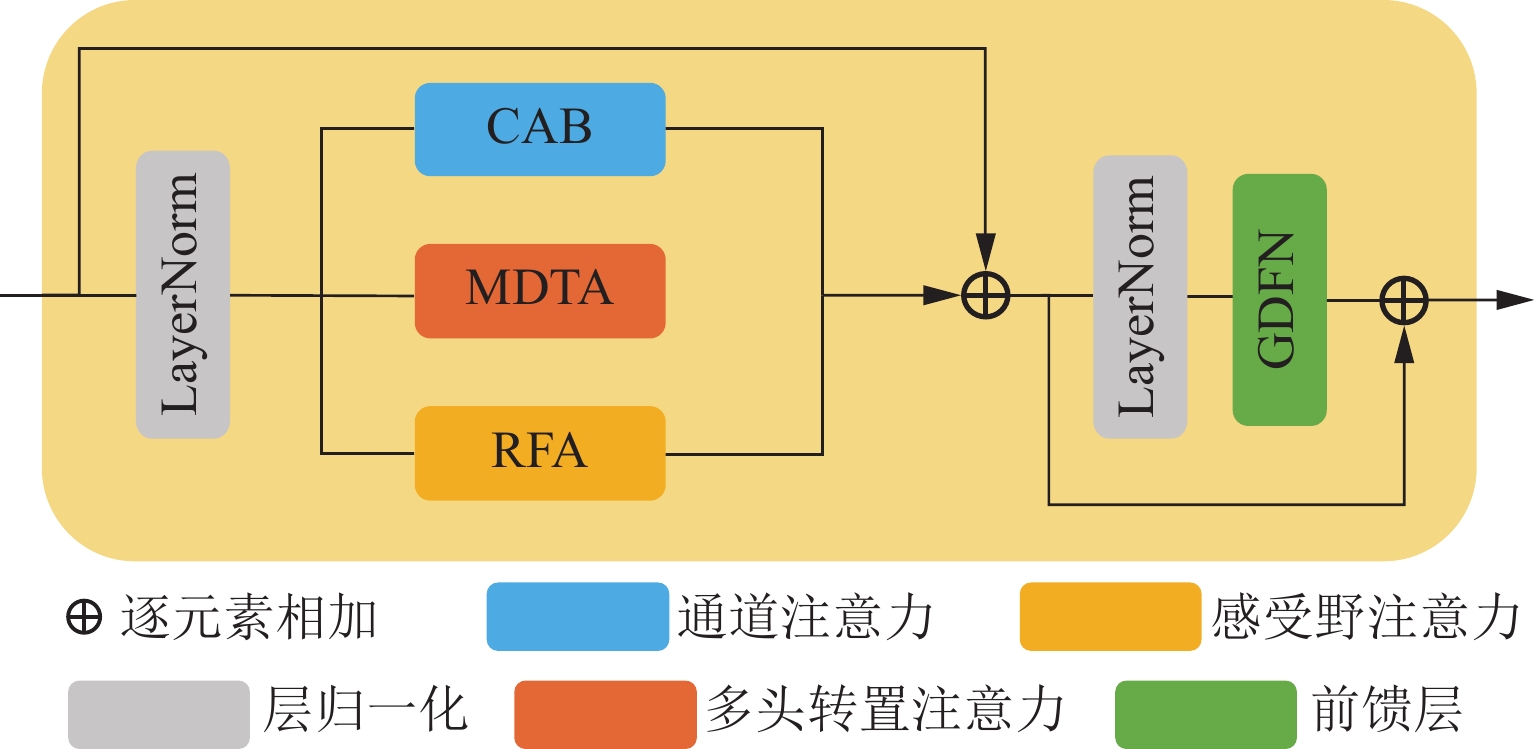
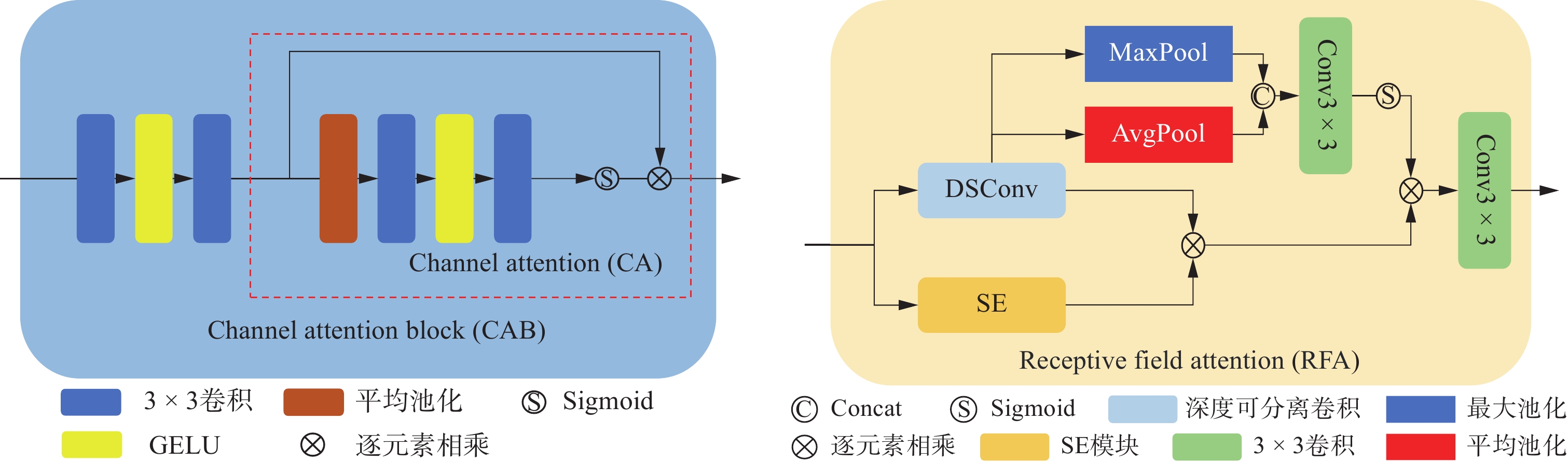
图 3 通道注意力和感受野注意力网络结构图
Figure 3. Network structure diagram of channel attention and receptive field attention
![]()
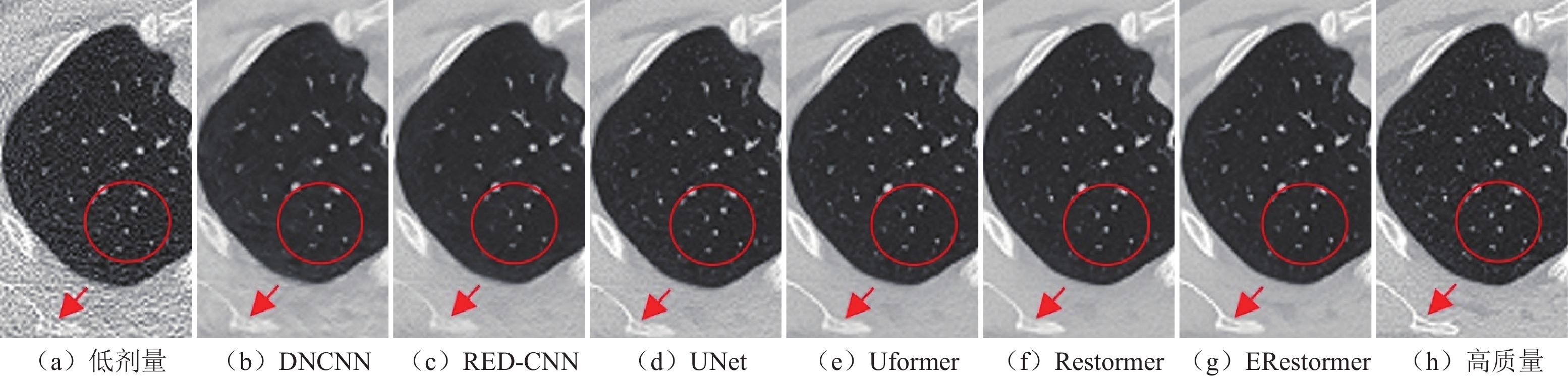
图 5 低剂量肺部CT图像去噪结果图;显示窗口为[0, 1]
Figure 5. Denoising results of low-dose lung CT images; the display window is [0, 1].
![]()
图 6 低剂量肺部CT图像去噪结果局部放大图;显示窗口为[0, 1]
Figure 6. Local magnification of denoising results of low-dose lung CT images; the display window is [0, 1].
![]()
图 7 低剂量肺部CT图像去噪结果图;显示窗口为[0, 1]
Figure 7. Denoising results of low-dose lung CT images; the display window is [0, 1]
![]()
图 8 低剂量肺部CT图像去噪结果局部放大图;显示窗口为[0, 1]
Figure 8. Local magnification of denoising results of low-dose lung CT image; the display window is [0, 1]
![]()
图 9 低剂量腹部CT图像去噪结果图;显示窗口为[0, 1]
Figure 9. Denoising results of low-dose abdominal CT images; the display window is [0, 1]
![]()
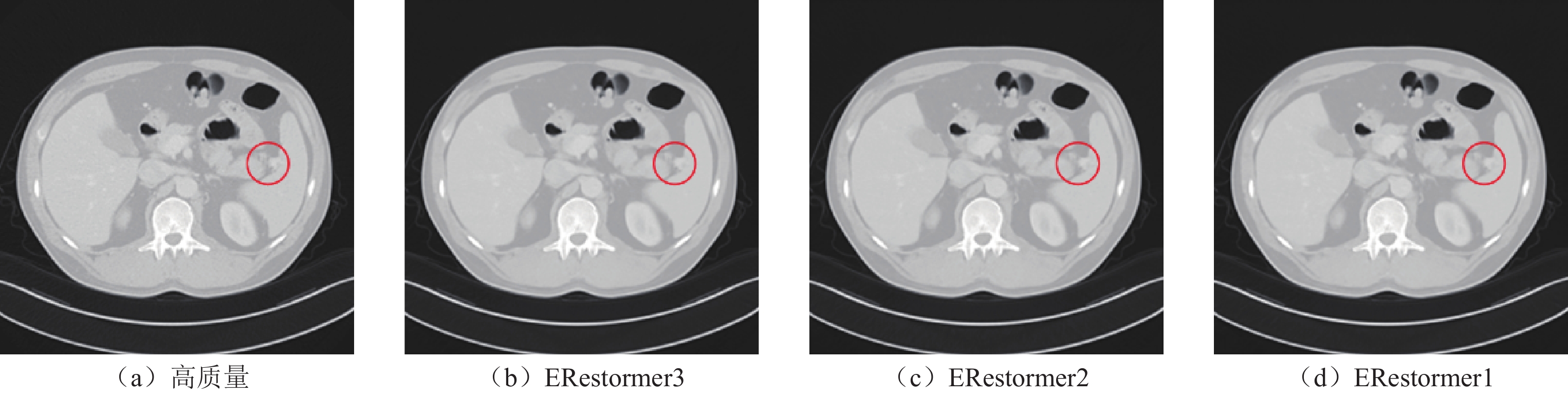
图 10 低剂量腹部CT图像去噪结果局部放大图;显示窗口为[0, 1]
Figure 10. Local magnification of denoising results of low-dose abdominal CT images; the display window is [0, 1]
![]()
图 11 低剂量肺部CT图像去噪结果图;显示窗口为[0, 1]
Figure 11. Denoising results of low-dose lung CT images; the display window is [0, 1]
![]()
图 12 低剂量肺部CT图像去噪结果局部放大图;显示窗口为[0, 1]
Figure 12. Local magnification of de-noising results of low-dose lung CT images; the display window is [0, 1]
表 1 6种网络的低剂量CT图像重建实验结果
Table 1 Results of low-dose CT image reconstruction experiments of six types of networks
算法 PSNR SSIM RMSE DNCNN 32.1194 0.8776 0.0268 RED-CNN 33.9776 0.8850 0.2226 UNet 34.7074 0.8935 0.0209 Uformer 34.9080 0.8961 0.0203 Restormer 34.9352 0.8963 0.0202 ERestormer 35.2355 0.8989 0.0196  下载: 导出CSV
下载: 导出CSV
表 2 消融实验结果
Table 2 Results of ablation experiment
消融实验 PSNR SSIM RMSE ERestormer 35.2355 0.8989 0.0196 no rfa+cab 34.9771 0.8974 0.0199 no ffm 35.1789 0.8984 0.0196 no rfa 35.1312 0.8981 0.0197 no cab 35.2045 0.8988 0.0196
下载: 导出CSV
表 3 特征融合模块逐层增加的定量结果比较
Table 3 Comparison of quantitative results of layer-by-layer addition of feature fusion modules
特征融合模块的位置 PSNR SSIM RMSE ERestormer3 35.2355 0.8989 0.0196 ERestormer3-2 35.2267 0.8986 0.0196 ERestormer3-2-1 35.2033 0.8985 0.0197
下载: 导出CSV
表 4 特征融合模块各层中的定量结果比较
Table 4 Comparison of quantitative results in each layer of feature fusion module
特征融合模块的位置 PSNR SSIM RMSE ERestormer3 35.2355 0.8989 0.0196 ERestormer2 35.1868 0.8982 0.0197 ERestormer1 35.1377 0.8977 0.0197
下载: 导出CSV
-
[1] BRENNER D J, HALL E J. Computed tomography—an increasing source of radiation exposure[J]. New England Journal of Medicine, 2007, 357(22): 2277-2284. DOI: 10.1056/NEJMra072149.
[2] QIAO Z, LU Y, LIU P, et al. An iterative reconstruction algorithm without system matrix for EPR imaging[J]. Journal of Magnetic Resonance, 2022, 344: 107307. DOI: 10.1016/j.jmr.2022.107307.
[3] QIAOZ, ZHANG Z, PAN X, et al. Optimization-based image reconstruction from sparsely sampled data in electron paramagnetic resonance imaging[J]. Journal of Magnetic Resonance, 2018, 294: 24-34. DOI: 10.1016/j.jmr.2018.06.015.
[4] QIAO Z, LIU P, FANG C, et al. Directional TV algorithm for image reconstruction from sparse-view projections in EPR imaging[J]. Physics in Medicine & Biology, 2024, 69(11): 115051.
[5] FANG C, XI Y, EPEL B, et al. Directional TV algorithm for fast EPR imaging[J]. Journal of Magnetic Resonance, 2024, 361: 107652. DOI: 10.1016/j.jmr.2024.107652.
[6] 马靓怡, 乔志伟. 基于Chambolle-Pock框架的核TV多通道图像重建算法[J]. CT理论与应用研究, 2022, 31(6): 731-747. DOI: 10.15953/j.ctta.2022.111. MA J Y, QIAO Z W. Nuclear TV multi-channel image reconstruction algorithms based on Chambolle-pock framework[J]. CT Theory and Applications, 2022, 31(6): 731-747. DOI: 10.15953/j.ctta.2022.111.
[7] 张家浩, 乔志伟. 基于相对TV最小的CT图像重建算法[J]. CT理论与应用研究, 2023, 32(2): 153-169. DOI: 10.15953/j.ctta.2022.190. ZHANG J H, QIAO Z W. Computed tomography reconstruction algorithm based on relative total variation minimization[J]. CT Theory and Applications, 2023, 32(2): 153-169. DOI: 10.15953/j.ctta.2022.190.
[8] LIU P, FANG C, QIAO Z. A dense and U-shaped transformer with dual-domain multi-loss function for sparse-view CT reconstruction[J]. Journal of X-Ray Science and Technology, 2024(Preprint): 1-22.
[9] LIU P, ZHANG Y, XI Y, et al. PU-CDM: A pyramid UNet based conditional diffusion model for sparse-view reconstruction in EPRI[J]. Biomedical Signal Processing and Control, 2025, 100: 107182. DOI: 10.1016/j.bspc.2024.107182.
[10] YAN H, FANG C, QIAO Z. A multi-attention Uformer for low-dose CT image denoising[J]. Signal, Image and Video Processing, 2024, 18(2): 1429-1442. DOI: 10.1007/s11760-023-02853-z.
[11] ZHANG K, ZUO W, CHEN Y, et al. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising[J]. IEEE Transactions on Image Processing, 2017, 26(7): 3142-3155. DOI: 10.1109/TIP.2017.2662206.
[12] CHEN H, ZHANG Y, KALRA M K, et al. Low-dose CT with a residual encoder-decoder convolutional neural network[J]. IEEE Transactions on Medical Imaging, 2017, 36(12): 2524-2535. DOI: 10.1109/TMI.2017.2715284.
[13] GUO S, YAN Z, ZHANG K, et al. Toward convolutional blind denoising of real photographs[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 1712-1722.
[14] ZHAO Y, JIANG Z, MEN A, et al. Pyramid real image denoising network[C]//2019 IEEE Visual Communications and Image Processing (VCIP). IEEE, 2019: 1-4.
[15] CHEN L, CHU X, ZHANG X, et al. Simple baselines for image restoration[C]//European conference on computer vision. Cham: Springer Nature Switzerland, 2022: 17-33.
[16] ANWAR S, BARNES N. Real image denoising with feature attention[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 3155-3164.
[17] CHEN J, YU Q, SHEN X, et al. ViTamin: Designing Scalable Vision Models in the Vision-Language Era[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 12954-12966.
[18] CHEN X, LI H, LI M, et al. Learning a sparse transformer network for effective image deraining[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 5896-5905.
[19] 乔一瑜, 乔志伟. 基于CNN和Transformer耦合网络的低剂量CT图像重建方法[J]. CT理论与应用研究, 2022, 31(6): 697-707+694. DOI: 10.15953/j.ctta.2022.114. QIAO Y Y, QIAO Z W. Low-dose CT image reconstruction method based on CNN and transformer coupling network[J]. CT Theory and Applications, 2022, 31(6): 697-707. DOI: 10.15953/j.ctta.2022.114.
[20] 樊雪林, 文昱齐, 乔志伟. 基于Transformer增强型U-net的CT图像稀疏重建与伪影抑制[J]. CT理论与应用研究, 2024, 33(1): 1-12. DOI: 10.15953/j.ctta.2023.183. FAN X L, WEN Y Q, QIAO Z W. Sparse reconstruction of computed tomography images with transformer enhanced U-net[J]. CT Theory and Applications, 2024, 33(1): 1-12. DOI: 10.15953/j.ctta.2023.183.
[21] 魏屹立, 杨子元, 夏文军, 等. 基于子空间投影和边缘增强的低剂量CT去噪[J]. CT理论与应用研究, 2022, 31(6): 721-729. DOI: 10.15953/j.ctta.2022.108. WEI Y L, YANG Z Y, XIA W J, et al. Low-dose CT denoising based on subspace projection and edge enhancement[J]. CT Theory and Applications, 2022, 31(6): 721-729. DOI: 10.15953/j.ctta.2022.108.
[22] VASWANI A. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017.
[23] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[C]//Proceedings of the 9th International Conference on Learning Representations. Austria: OpenReview. net, 2021.
[24] LIU Z, LIN Y, CAO Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 10012-10022.
[25] WANG Z, CUN X, BAO J, et al. Uformer: A general u-shaped transformer for image restoration[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 17683-17693.
[26] ZAMIR S W, ARORA A, KHAN S, et al. Restormer: Efficient transformer for high-resolution image restoration[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 5728-5739.
[27] WANG T, ZHANG K, SHEN T, et al. Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2023, 37(3): 2654-2662.
[28] XU S, SUN Z, ZHU J, et al. DemosaicFormer: Coarse-to-Fine Demosaicing Network for HybridEVS Camera[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 1126-1135.
[29] OUYANG D, HE S, ZHANG G, et al. Efficient multi-scale attention module with cross-spatial learning[C]//ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023: 1-5.
[30] TU Z, TALEBI H, ZHANG H, et al. Maxim: Multi-axis mlp for image processing[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 5769-5780.
[31] CHEN X, WANG X, ZHOU J, et al. Activating more pixels in image super-resolution transformer[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023: 22367-22377.
[32] ZHANG X, LIU C, YANG D, et al. RFAConv: Innovating spatial attention and standard convolutional operation[J]. ArXiv, 2304: abs/2304.03198.
[33] DAI Y, GIESEKE F, OEHMCKE S, et al. Attentional feature fusion[C]//Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2021: 3560-3569.






计量
- 文章访问数: 313
- HTML全文浏览量: 35
- PDF下载量: 37


