
-
摘要: 能谱CT可产生不同X射线能量下的基材料图像,所产生的基材料图像可用于组织成分和造影剂分布的定性与定量评价,且对成像物质分离、鉴别的能力明显优于传统单能CT。能谱CT中双能谱技术是最常用的模式之一,在临床应用中发挥了重大作用。本文就双能谱CT图像域基材料分解的两物质分解、多物质分解方法进行总结,最后展望未来可能的发展方向。Abstract: Spectral CT can produce basis materials with different X-ray energies. Subsequently, the generated basis materials can be used for qualitative and quantitative evaluation of tissue components and contrast agent distribution. This approach presents a superior ability to separate and identify imaging materials compared to traditional single-energy CT. Dual-energy spectrum technology is one of the most commonly used modes in spectrum CT, which plays an important role in clinical application. In this study, the decomposition methods of a basis material in the image domain of dual-energy spectrum CT were classified into two categories: two-material decomposition and multi-material decomposition. Finally, these methods are summarized and trend of future development is addressed.
-
Keywords:
- spectral CT /
- dual-energy CT /
- image domain /
- basis material decomposition
-
视频对象分割(video object segmentation,VOS)作为视频检索、编辑等各种视频应用的重要步骤,越来越受到人们的关注。基于用户交互,现有的VOS算法有两种常见的设置:无监督VOS和半监督VOS。无监督VOS[1-8]在没有人为干预的情况下,直接分割视频中的主要对象,这些物体通常位于显著区域。而半监督VOS[9-15]给出第1帧的ground truth分割,并将标记的对象信息传播到后续帧中。然而,它需要对每个单独视频的第1帧进行像素级注释,这限制了处理大量视频的可扩展性。虽然交互式VOS[16-17]进一步将所需人力减少到几个笔画,但所提供的信息对于跨帧分割可能过于粗糙。为了在语义分割和跨视频处理之间进行权衡,最近的研究[18-20]利用了自然语言和类标签等新的交互作用。
周期运动视频是指在视频序列中呈现明显重复运动的场景,如人体行走、交通工具移动或机械装置的循环往复动作。周期运动视频对象分割是一个重要技术,专注于从这些视频中提取和跟踪具有周期模式的运动对象。通过分析视频帧序列中的运动模式,该技术能够识别并分离出具有重复运动的对象,为视频监控、运动分析、虚拟现实和医学影像[21-24]等领域提供重要支持。
借助计算机视觉(computer vision,CV)和深度学习(deep learning,DL)技术,周期运动视频对象分割不仅提高了对复杂动态场景的理解能力,还为视频内容的深入理解和应用提供了更为精细的解决方案。随着网络视频数量的迅速增加,周期运动视频对象分割在视频检索、编辑等方面逐渐成为备受关注的研究热点。
1. 相关工作
本文旨在解决少样本周期视频图像分割的问题,这是一个尚未完全解决的挑战。本文提出一种新的方法,通过利用带有注释的支持图像来增强在不同场景下同类目标的分割结果。这些支持图像可以在查询视频之外随机选择,从而提高模型的泛化能力,能够在语义分割和跨视频处理之间取得平衡,满足实际情况下网络视频激增的应用需求。
本文的核心技术包括卷积长短期记忆网络(convolutional LSTM network,ConvLSTM)和交叉注意力机制(cross-attention mechanism)。ConvLSTM能够有效地捕捉视频序列中的长期依赖关系,而交叉注意力机制则能够帮助模型更好地理解不同场景下的目标。因此本文的方法在少样本周期视频图像分割任务上取得了很好的效果。
1.1 卷积长短期记忆网络
卷积长短期记忆网络[25]是一种将卷积神经网络(convolutional neural networks,CNN)[26]和长短期记忆(long short-term memory,LSTM)[27]相结合的深度学习模型,适用于时间序列图像(如视频)的建模。与传统全连接LSTM相比,ConvLSTM在处理时空相关性方面具有更强的性能,其创新之处在于将卷积操作引入LSTM结构中,以更有效地捕捉时空上下文信息。
在ConvLSTM中,除了传统的输入门、遗忘门和输出门外,还存在卷积操作。每个ConvLSTM单元由一个细胞状态(cell state,C)和一个隐藏状态(hidden state,H)组成,其中细胞状态类似于传统LSTM中的记忆细胞。
当输入特征映射进入ConvLSTM单元时,卷积操作可以有效地捕捉空间信息,并与LSTM结构相结合,使得ConvLSTM能够处理时间序列图像。在ConvLSTM中,输入门、遗忘门和输出门的计算方式与传统LSTM相似,但是它们与卷积操作结合,使得ConvLSTM能够更好地处理时空相关性。
ConvLSTM的记忆门允许细胞状态逐渐积累信息,以适应时间序列图像中的长期依赖关系。当输入门被激活时,新的信息被添加到细胞状态中;而当遗忘门被激活时,过去的记忆则被遗忘。最终,输出门和当前细胞状态经过卷积,得到了ConvLSTM的输出。
通过将LSTM单元中的全连接层替换为输入门、遗忘门和输出门的卷积运算,构造ConvLSTM单元如图1所示,ConvLSTM方程如式(1)所示,
$$ \left\{ \begin{aligned} & {\boldsymbol{i}_t} = \delta \Big( {{\boldsymbol{W}_{xi}}*{\boldsymbol{x}_{_t}} + {\boldsymbol{W}_{hi}}*{\boldsymbol{h}_{_{t - 1}}} + {\boldsymbol{W}_{ci}} \circ {\boldsymbol{c}_{_{t - 1}}} + {\boldsymbol{b}_i}} \Big) \\ &{\boldsymbol{f}_t} = \delta \Big( {{\boldsymbol{W}_{xf}}*{\boldsymbol{x}_{_t}} + {\boldsymbol{W}_{hf}}*{\boldsymbol{h}_{_{t - 1}}} + {\boldsymbol{W}_{cf}} \circ {\boldsymbol{c}_{_{t - 1}}} + {\boldsymbol{b}_f}} \Big) \\ & {\boldsymbol{c}_t} = {\boldsymbol{f}_t} \circ {\boldsymbol{c}_{_{t - 1}}} + {\boldsymbol{i}_t} \circ \tanh \Big( {{\boldsymbol{W}_{xc}}*{\boldsymbol{x}_{_t}} + {\boldsymbol{W}_{hc}}*{\boldsymbol{h}_{_{t - 1}}} + {\boldsymbol{b}_c}} \Big) \\ & {\boldsymbol{o}_t} = \delta \Big( {{\boldsymbol{W}_{xo}}*{\boldsymbol{x}_{_t}} + {\boldsymbol{W}_{ho}}*{\boldsymbol{h}_{_{t - 1}}} + {\boldsymbol{W}_{co}} \circ {\boldsymbol{c}_{_{t - 1}}} + {\boldsymbol{b}_o}} \Big) \\ & {\boldsymbol{h}_t} = {\boldsymbol{o}_t} \circ \tanh ({\boldsymbol{c}_t}) \end{aligned}\right. \text{,} $$ (1) 其中, * 表示卷积算子,而
$ \circ $ 表示Hadamard积。Wx、Wh和Wc表示相应门的卷积核。xt是ConvLSTM模块的输入,ht表示隐藏的输出。ConvLSTM通过将卷积操作与LSTM结构相结合,能够更有效地处理时空序列图像,并在时间序列图像建模任务中能够取得显著的性能提升。
1.2 交叉注意力机制
交叉注意力机制[28-30]是一种重要注意力机制,常用于处理包含多个输入序列或模态(如文本和图像)的情况。与自注意力机制[31-32]不同,交叉注意力机制允许模型关注不同输入序列间的交叉关系,从而更好地捕获它们之间的语义相关性。
在交叉注意力机制中,通常存在两种类型的序列:查询序列和键值序列。查询序列通常是模型要关注的序列,而键值序列包含用于计算注意力权重的信息。例如,在将图像和文本进行关联时,文本可作为查询序列,而图像可作为键值序列。交叉注意力机制的核心思想是,对于查询序列中的每个元素,模型都会根据键值序列中的信息来计算其上下文表示。具体来说,对于查询序列中的每个元素,交叉注意力机制计算该元素与键值序列中每个元素之间的相似度,并根据这些相似度来计算加权和,从而获得该元素的上下文表示。这样,模型能够根据键值序列中的信息来调整查询序列中的表示,从而更好地捕获它们之间的语义关系。
交叉注意力机制在多模态任务中得到了广泛应用,例如图像标注、视觉问答和图像生成等领域。它能够有效地将不同模态的信息整合起来,提高模型对复杂任务的理解和处理能力。本文采用交叉注意力机制将近似类别或同类别不同环境的视频图像之间建立联系,从而增强在少样本新场景下的模型分割能力,提高了模型的泛化能力。
2. 基于LSTM与交叉注意力机制的分割模型
本文每个训练集合包括支持集和同类标签的查询集,每个支持集和查询集包含相同图片组个数,每个图片组包含当前帧以及前后两帧共3帧。支持集中每张图片在与查询集同类标签下都有一张标签,网络学习预测查询集中所有帧的预测标签。
2.1 周期计算
首先对视频数据序列估计周期,将视频中第1个周期序列用作训练集,后面的视频序列做测试集。由于周期运动从任一时刻开始,每经过一定时间,就恢复到开始时刻。因此对视频序列所有图像计算与第1帧的皮尔逊相关系数:
$$ {\rho _{{\boldsymbol{XY}}}} = \frac{{{{\mathrm{cov}}} ({\boldsymbol{X}},{\boldsymbol{Y}})}}{{{\sigma _{\boldsymbol{X}}}{\sigma _{\boldsymbol{Y}}}}} = \frac{{E\Big( {\Big( {{\boldsymbol{X}} - {\mu _{\boldsymbol{X}}}} \Big)\Big( {{\boldsymbol{Y}} - {\mu _{\boldsymbol{Y}}}} \Big)} \Big)}}{{{\sigma _{\boldsymbol{X}}}{\sigma _{\boldsymbol{Y}}}}} \text{,} $$ (2) 其中:
$ {\mu }_{{\boldsymbol{X}}} $ 和$ {\sigma }_{{\boldsymbol{X}}} $ 分别是$ \boldsymbol{X} $ 的均值和标准差,$ {\mu }_{{\boldsymbol{Y}}} $ 和$ {\sigma }_{{\boldsymbol{Y}}} $ 是$ \boldsymbol{Y} $ 的均值和标准差。对所得相关系数的时间序列记为T,进行归一化将序列映射到
$[-1,1] $ 之间:$$ {{T}} = \frac{{2\big( {{{T}} - {{{T}}_{\min }}} \big)}}{{{{{T}}_{\max }} - {{{T}}_{\min }}}} - 1 。 $$ (3) 然后将序列T在频谱分析,根据提取幅值频谱的峰值,以确定其具体周期,依据周期估计结果,将第1个周期序列作为训练集的查询集。
2.2 模型框架
模型主要由3个部分组成:编码器网络,LCA(LSTM与交叉注意力机制)模块和解码器网络(图2)。给定支持集的多个查询集作为输入,两个具有相同权重的编码器分别为支持集和查询集提取特征,对查询集特征通过ConvLSTM层增强时序相关特征,然后通过交叉注意力机制,计算支持集和查询集之间的相关性,得出注意力特征。将注意力特征与查询集特征连接起来,使用解码器来预测最终的分割结果。
ResNet-50(deep residual network)是一个经典的深度学习模型,在ImageNet数据集上取得了很好的性能,并且具有较深的网络结构,能够捕获更复杂的特征,从而在许多视觉任务中表现出色。先前工作[33]发现,在少样本场景中,深度学习网络高层的特征的泛化程度较低。因此,本文使用在ImageNet[34]上预训练的ResNet-50[35]以获得通用特征表示。
经过LCA模块处理后,将查询集的特征值先进行时序增强,再与注意特征连接起来,然后发送到解码器。本文基于上采样操作和跳跃连接来设计解码器。首先,对特征进行上采样,以恢复到输入图像的大小;同时,通过跳跃连接将查询帧的底层特征融合到上样本特征中;最终,通过解码器预测查询集的分割标签。
2.3 LCA模块
计算支持集和查询集图像之间的相关性通常涉及多对多关注矩阵的计算。本文通过两个较小矩阵乘积取代多对多注意力矩阵,并在其中嵌入ConvLSTM模块,增强了注意力矩阵的时序相关性。
如图3所示,将从编码层得到的查询集特征、支撑集特征,各自通过3个3×3卷积核,将特征通过线性变换,得到各自的q、k、
$ \boldsymbol{v} $ 。由于查询集是多视频帧具有时序相关性,因此将查询集输入到ConvLSTM模块中,以便模型能够更好地理解视频中的时序相关性和周期性。对时序性增强后的查询集q、k特征与支持集的k、$ \boldsymbol{v} $ 特征,计算注意力特征。域代理网络(domain agent network,DAN)[36]发现,从一帧学习到的注意力特征可近似于其他帧的注意特征。因此,采用中间帧作为一段视频的代替,保证学习到的注意力特征的信息性。通过采用查询集的q与k的中间帧和支持集的k与查询集q中间帧相乘的两个小矩阵乘法,代替查询集的q与支持集的k的大矩阵乘法。使计算复杂度从指数增加降为线性增加。
查询特征通过单个卷积层映射到查询
$ {\boldsymbol{q}}^{Q} $ 和键值对$ {\boldsymbol{k}}^{Q} $ -$ {\boldsymbol{v}}^{Q} $ 。类似地,支持特性映射到查询$ {{\boldsymbol{q}}}^{S} $ 和键值对$ {{\boldsymbol{k}}}^{S} $ -$ {{\boldsymbol{v}}}^{S} $ :$$ \left\{ {\begin{aligned} & {{{\boldsymbol{q}}^Q} \in {\mathbb{R}^{N \times {L_q}}},\;\;{{\boldsymbol{q}}^S} \in {\mathbb{R}^{M \times {L_q}}},\;\;{{{L}}_{\boldsymbol{q}}} = H \times W \times {C_q}} \\ &{{{\boldsymbol{k}}^Q} \in {\mathbb{R}^{N \times {L_k}}},\;\;{{\boldsymbol{k}}^S} \in {\mathbb{R}^{M \times {L_k}}},\;\;{{{L}}_{\boldsymbol{k}}} = H \times W \times {C_k}} \\ &{{{\boldsymbol{v}}^Q} \in {\mathbb{R}^{N \times {L_v}}},\;\;{{\boldsymbol{v}}^S} \in {\mathbb{R}^{M \times {L_v}}},\;\;{{{L}}_{\boldsymbol{v}}} = H \times W \times {C_v}} \end{aligned}} \right. 。 $$ (4) 将
$ {\boldsymbol{q}}^{Q} $ 和$ {\boldsymbol{k}}^{Q} $ 经过ConvLSTM模块后记为$ {\boldsymbol{q}}^{{Q}_{L}} $ 和$ {\boldsymbol{k}}^{{Q}_{L}} $ , 对$ {\boldsymbol{q}}^{{Q}_{L}} $ 和$ {\boldsymbol{k}}^{{Q}_{L}} $ 采用中间帧t作为一段视频的代替记为$ {\boldsymbol{q}}^{{Q}_{L}t} $ 和$ {\boldsymbol{k}}^{{Q}_{L}t} $ ,计算出$ {\boldsymbol{q}}^{{Q}_{L}} $ 与$ {\boldsymbol{k}}^{{Q}_{L}t} $ 的注意力矩阵$ {\boldsymbol{A}}^{Qt} $ 和$ {\boldsymbol{q}}^{{Q}_{L}t} $ 与$ {\boldsymbol{k}}^{S} $ 的注意力矩阵$ {\boldsymbol{A}}^{tS} $ :$$ {{\boldsymbol{A}}^{Qt}} = \sigma \left( {\frac{{{{\boldsymbol{q}}^{{Q_L}}}{{({{\boldsymbol{k}}^{{Q_L}t}})}^{\mathrm{T}}}}}{{\sqrt {{{\boldsymbol{C}}_k}} }}} \right);\;\;{A^{tS}} = \sigma \left( {\frac{{{{\boldsymbol{q}}^{{Q_L}t}}{{({{\boldsymbol{k}}^s})}^{\mathrm{T}}}}}{{\sqrt {{{\boldsymbol{C}}_k}} }}} \right) 。 $$ (5) 对得到的注意特征矩阵
$ {\boldsymbol{A}}^{Qt} $ 和$ {\boldsymbol{A}}^{tS} $ ,通过式(4)计算得到关注特征$ {\boldsymbol{v}}^{A} $ 。$$ {{\boldsymbol{v}}^A} = {\boldsymbol{A}}{{\boldsymbol{v}}^S} = {{\boldsymbol{A}}^{Qt}}{{\boldsymbol{A}}^{tS}}{{\boldsymbol{v}}^S} , $$ (6) 其中首先计算
$ {\boldsymbol{A}}^{tS}{\boldsymbol{v}}^{S} $ ,以避免存储和计算大矩阵A:$$ {\boldsymbol{A}} = \sigma \left( {\frac{{{\boldsymbol{q}}{{({\boldsymbol{k}})}^{\mathrm{T}}}}}{{\sqrt {{{\boldsymbol{C}}_k}} }}} \right) 。 $$ (7) 综上所述,本文模块的显存消耗和时间复杂度分别为
$ O\left(\big(N+M\big){\big(HW\big)}^{2}\right) $ 和$ O\left(\big(N+M\big){\big(HW\big)}^{2}C\right) $ ,而全阶注意模块的显存消耗和时间复杂度分别为$ O\left(\big(NM\big){\big(HW\big)}^{2}\right) $ 和$ O\left(\big(NM\big){\big(HW\big)}^{2}C\right) $ 。2.4 ConvLSTM模块
通过两个小矩阵乘法代替大矩阵乘法可降低计算复杂度,但是通过中间帧代替一段视频,随着查询集的增加,其时间相关性差异较大,限制了模型性能的增长,本文采用3D的ConvLSTM[37]可有效遏制这个问题。
对通过卷积层得到的q、k特征,按时间顺序分为3个图片组(图4)。从输入特征映射中复制初始存储单元,并根据特征的输入顺序更新存储单元。具体来说,从q、k特征中提取的特征映射x1中复制初始隐藏状态和存储单元。然后,ConvLSTM动态累积隐藏状态和来自存储单元的特征映射,计算出最后一个隐藏状态,即h3。将h1、h2、h3按时间顺序依次拼接,得到时序增强的特征。
3. 实验结果
3.1 周期数据集
本文基于Youtube-VIS建立训练集。该训练集由
2238 个Youtube视频组成,包含3774 个实例,涵盖40个类别。本文研究少样本周期视频分割问题,因此通过采用每个视频每个类别的前3或5个图片组作为训练集,其余作为测试集以达到少样本的目的。以5个图片组为例,支持集是增强被预测类别图像的分割效果,可由任意图片或者视频构成,不需具备周期性。因此,从单个类中随机抽取5个图像,并且取每个图像相邻两帧共计15帧作为支持集。查询集是被预测类别的图像,由于Youtube-VIS数据集不含周期视频,因此通过以下方式制作周期视频,3个图片组构造如图5(a)所示,5个图片组构造如图5(b)所示。以5个图片组为例,首先从与支持集的同类其他的完整视频中连续采样4个图像,再将第五张图像复制第一张图像制作成周期为4的视频图像序列,并取每个图像相邻两帧共计15帧,制成5个图片组的周期视频数据。为保证训练结果置信度,训练集和测试集保持独立。
3.2 实验环境
本文使用Adam(adaptive moment estimation)作为模型优化器。将学习率设置为10−5,交叉熵损失和IOU损失在
$ 5{{L}}_{\mathrm{c}\mathrm{e}}+{{L}}_{\mathrm{i}\mathrm{o}\mathrm{u}} $ 相结合用于训练,进行了100次迭代,批大小为2。本文实验环境都是在RTX2080 ti-11 G,Inter Xeon Silver4216 @ 2.10 GHz环境中训练测试。相较于大模型的视频图像分割背景下,本文模型更加轻量化,以极小的计算花费,利用视频图像分割任务中的时空上下文信息,并且首次针对周期视频分割任务提出了有效的解决方案,验证了本文模型在周期视频中的有效性。通过将批大小设为1,对比本文模型、DAN、ConvLSTM、ResNet模型的显存消耗。
由表1可见,本文模型训练时显存消耗6.27 Gbit,属于轻量型模型,可在
1080 ti-8 G及以上配置部署,相较于DAN模型仅增加了0.05 Gbit,相较于ConvLSTM、ResNet也只增加了1.4~1.8 Gbit。从性能来看,这些计算消耗的增加是必要的,具体性能分析在3.4中详细介绍。表 1 各模型的显存使用Table 1. Memory use of each model模型 显存/Gbits ResNet 4.83 ConvLSTM 4.46 DAN 6.22 Ours 6.27 3.3 评价指标
视频目标分割评价指标包括轮廓精确度(contour accuracy)和区域相似度(region similarity)。
区域相似度(region similarity):预测的掩膜M和真实标注G之间相交与联合区域之比,衡量了像素预测错误的程度。
$$ J = \frac{{{|\boldsymbol{M}} \cap {\boldsymbol{G}|}}}{{|{\boldsymbol{M }}\cup {\boldsymbol{G}}}|} 。 $$ (8) 轮廓准确度(contour accuracy):在预测的掩膜M和真实标注G的轮廓点集之间,计算基于轮廓的查准率
$ {P}_{c} $ 和召回率$ {R}_{c} $ ,两者的调和平均数即为准确度F,衡量了分割边界的准确程度。$$ F = \frac{{2{P_c}{R_c}}}{{{P_c} + {R_c}}} 。 $$ (9) 本文使用区域相似度(J)与轮廓相似度(F)来衡量模型性能。
3.4 普通视频应用
为了验证本文模型的有效性,与DAN、ConvLSTM、ResNet模型性能在区域相似度(
$ J $ )和轮廓相似度($ F $ )来进行对比。对查询集和支持集分别为3或5图像组的周期数据集对本文模型、DAN、ConvLSTM、ResNet模型进行训练和测试,结果如表2和表3所示。表 2 各模型在3图像组上的性能对比Table 2. Performance comparison of each model on 3 image groups模型 J F ResNet 0.553 0.592 ConvLSTM 0.530 0.569 DAN 0.637 0.687 Ours 0.642 0.691 表 3 各模型在5图像组上的性能对比Table 3. Performance comparison of ecah model on 5 image groups模型 J F ResNet 0.555 0.605 ConvLSTM 0.551 0.599 DAN 0.665 0.715 Ours 0.675 0.730 本文模型相对ResNet和ConvLSTM性能提升在10%左右,相对DAN模型也在两个指标平均提高了0.5% 到1.5%,并且随着查询集的增加(即从3增加到5),本文模型性能提高了3.28% 和3.91%,相比于DAN模型提升的2.8% 和2.87%,提升速度大于DAN模型。
本文模型在处理周期视频有一定的优越性,对查询集和支持集都为5图像组的周期数据集和非周期数据集上训练本文模型和DAN模型,结果如表4所示。
表 4 各模型在周期与非周期数据上性能对比Table 4. Performance comparison of each models on periodic and aperiodic data数据 模型 J F 非周期 DAN 0.680 0.728 非周期 Ours 0.671 0.719 周期 DAN 0.665 0.715 周期 Ours 0.675 0.730 本文对各模型分割结果进行详细对比。如图6和图7所示,ResNet存在大范围分割缺失情况,图6左边的鸭子存在多次未检测到,图7中蛇的躯干多张图分割缺失。ConvLSTM分割结果前后连续性较好,图6后3帧中,鸭头部分分割,图7中存在部分图片躯干未预测到,随着时间增加,分割效果逐渐变差。DAN在鸭子分割中形态较为完整,但分割结果前后独立,存在较多小面积细节分割缺失情况,图7中对蛇分割个别存在躯干分割缺失,躯干边界分割不够光滑。本文模型分割结果前后连续性较好,图6的鸭子和图7中的蛇存在个别细节分割缺失的问题,在图7中对蛇躯干部分分割较为光滑,基本不存在躯干缺失。
综上所述,本文模型分割结果均优于对比模型。
3.5 医学视频应用
进一步将本文模型应用于医学图像领域的鸡胚胎近似周期运动进行少样本视频图像分割。ResNet在医学图像的血管分割任务上,表现不是十分理想,并且U-Net[38]其独特的结构能够有效地满足医学图像中结构的大小变化、形状复杂性以及需要精确边缘定位的要求。将本文模型与DNA模型分别在ResNet和Unet编解码网络下进行对比实验。
由表5可见,本文模型在ResNet和Unet性能都优于DAN模块。在区域相似度上,本文模型在Unet网络下,相较于DAN提升了12.92%,相较于Unet提升了8.85%。在轮廓相似度上,本文模型相较于DAN提升了20.09%,相较于Unet提升了12.89%。
表 5 各模型鸡胚胎分割性能对比Table 5. Comparison of chicken embryo partitioning of each models模型 J F DAN+ResNet 0.140 0.075 LCA+ResNet 0.331 0.252 Unet 0.511 0.777 DAN+Unet 0.470 0.705 LCA+Unet 0.599 0.906 对预测结果进行可视化分析,如图8所示,对比了本文模型与Unet、DAN+Unet模型对不同数据扩增角度的数据集预测结果。由图8可见,3个模型对于鸡胚胎血管形状结构都能很好地学习到。在不同角度中,本文提出的LCA结合Unet后,分割的轮廓更加精准,边缘结果更加精细。在血管末端部分,本文模型能将毛细血管很好地与背景分割出来。Unet、DAN+Unet模型轮廓分割较模糊,边缘分割不准确,毛细血管分割存在粘连在一起的情况,相对于本文模型效果较差。
![]() 图 8 各模型鸡胚胎分割结果对比Figure 8. Comparison of chicken embryo segmentation results of each models
图 8 各模型鸡胚胎分割结果对比Figure 8. Comparison of chicken embryo segmentation results of each models4. 讨论
由以上结果可见,ResNet模型分割结果在时间连续性上较差,但能在连续分割过程中,不受之前分割结果影响,能发现之前帧未分割到的部分。ConvLSTM有效地结合了时序信息,在连续视频分割中不会存在大面积信息突然缺失行为,但随着时间增长,模型分割性能会不断降低。DAN模型形态分割较为完美,但是缺乏时间连续性,对连续视频在局部分割中仍存在信息缺失的问题。
本文模型有效地结合了时序信息,很少出现分割大范围缺失现象,降低了DAN模型在局部分割缺失的问题,相较于ConvLSTM模型,解决了随着时间增长模型分割性能越来越差的问题。但是在部分细节仍然存在缺失,对边缘轮廓更精确的分割,仍是该领域值得持续研究的问题。
5. 结论
本文提出了基于LSTM与交叉注意力机制的视频图像分割模型和制作周期视频图像序列的简洁方法,尝试解决少样本周期视频图像分割问题。
通过ConvLSTM与交叉注意力机制相结合,解决了DAN模型随着样本数增长,模型性能提升较差的问题。对周期视频分割问题提出有效的解决方案,以较小的计算代价处理少样本周期视频的图像分割问题,在少样本周期视频数据集中取得了良好结果。
-
![]()
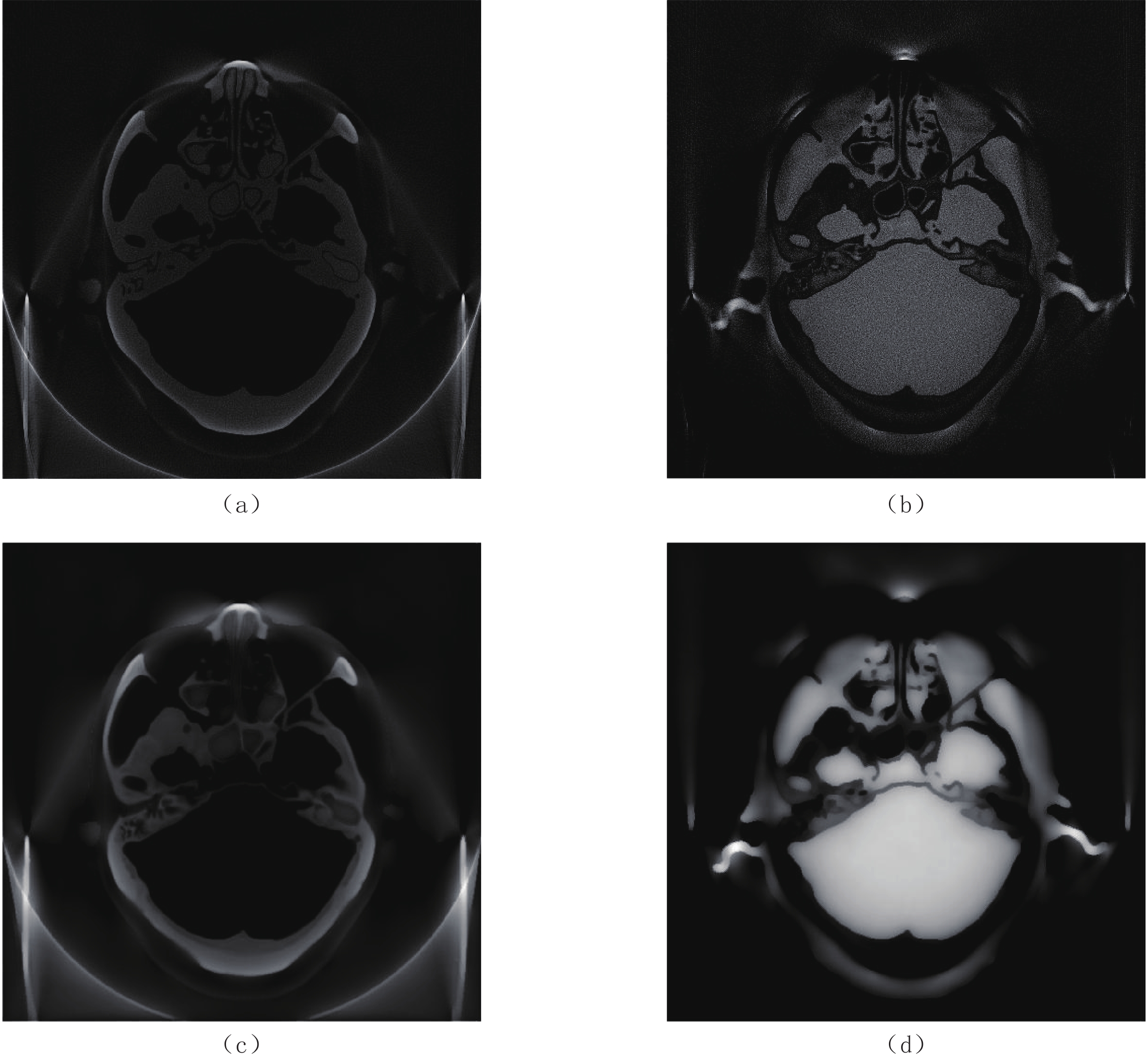
图 1 两种分解方法的模拟复现结果
(a)和(b)是直接矩阵求逆法分解的骨和软组织的基材料图像;(c)和(d)是迭代分解法分解的骨和软组织的基材料图像。
Figure 1. Simulation results obtained with the two decomposition methods
表 1 两种解决方案的主要研究
Table 1 Main research of two solutions
方法 文献 时间 优点 缺点 分解后去噪 [13] 1976 方法实现简单,计算效率高 由于图像分辨率损失很大,效果有限 [14] 1984 实现简便 效果有限 [15] 1985 实现简单 效果有限 [16] 1988 缓解了空间分辨率损失的问题 有边缘伪影 [17] 1995 算法可以在不考虑噪声相关性的情况下实现
噪声抑制分解后的图像中高频噪声被过度抑制,导致图像纹理的改变 [18] 2003 算法利用CT或分解图像的冗余结构或统计信
息进行噪声抑制,可以更好地抑制噪声没有完全描述DECT图像和分解图像之间的映射关系 分解前去噪 [19] 2014 使重建的两幅CT图像噪声变得强烈相关,进
而使得分解图像的噪声得到显著抑制CT重建和图像分解的结合增加了计算的复杂性,并且算法需要大量迭代才能收敛 [20] 2015 可以在保留定量测量和高频边缘信息的同
时显著降低噪声在心肌成像中仍会存在边缘效应 [21] 2018 在抑制噪声的同时可以保持图像边缘细节 没有考虑分解过程的噪声对图像的影响 [22] 2019 可获得高质量的重建CT图像以便后续分解 没有考虑分解过程的噪声对图像的影响  下载: 导出CSV
下载: 导出CSV
表 2 基于深度学习方法分解图像的主要研究
Table 2 Main research of image decomposition based on deep learning method
下载: 导出CSV
-
[1] 高海英. 能谱CT成像关键参数检测技术研究[D]. 广州: 南方医科大学, 2015. GAO H Y. Study on testing techniques of spectral CT imaging key parameters[D]. Guangzhou: Southern Medical University, 2015. (in Chinese).
[2] 韩文艳. CT能谱成像的基本原理与临床应用优势[J]. 中国医疗设备, 2015,30(12): 90−91. doi: 10.3969/j.issn.1674-1633.2015.12.025 HAN W Y. Basic principle and advantages of clinical application of CT energy spectrum imaging[J]. China Medical Devices, 2015, 30(12): 90−91. (in Chinese). doi: 10.3969/j.issn.1674-1633.2015.12.025
[3] ALVAREZ R E, MACOVSKI A. Energy-selective reconstructions in X-ray computerized tomography[J]. Physics in Medicine & Biology, 1976, 21(5): 733−744.
[4] 王丽新, 孙丰荣, 仲海, 等. 双能CT成像的数值仿真[J]. 航天医学与医学工程, 2015,28(5): 350−357. WANG L X, SUN F R, ZHONG H, et al. Numerical simulation of dual-energy CT imaging[J]. Space Medicine & Medical Engineering, 2015, 28(5): 350−357. (in Chinese).
[5] MAASS C, BAER M, KACHELRIESS M. Image-based dual energy CT using optimized precorrection functions: A practical new approach of material decomposition in image domain[J]. Medical Physics, 2009, 36(8): 3818−3829. doi: 10.1118/1.3157235
[6] 贺芳芳. 能谱CT基物质分解技术应用研究[D]. 济南: 山东大学, 2020. HE F F. Application research on basis material decomposition of spectral CT[D]. Jinan: Shandong University, 2020. (in Chinese).
[7] MENDONÇA P R S, BHOTIKA R, MADDAH M, et al. Multi-material decomposition of spectral CT images[C]//Medical Imaging 2010: Physics of Medical Imaging. SPIE, 2010, 7622: 633-641.
[8] 周正东, 章栩苓, 辛润超, 等. 基于MAP-EM算法的双能CT直接迭代基材料分解方法[J]. 东南大学学报(自然科学版), 2020,50(5): 935−941. doi: 10.3969/j.issn.1001-0505.2020.05.020 ZHOU Z D, ZHANG X L, XIN R C, et al. Direct iterative basis material decomposition method for dual-energy CT based on MAP-EM algorithm[J]. Journal of Southeast University (Natural Science Edition), 2020, 50(5): 935−941. (in Chinese). doi: 10.3969/j.issn.1001-0505.2020.05.020
[9] 孙英博, 孔慧华, 张雁霞. 基于投影域分解的多能谱CT造影剂物质识别研究[J]. 中北大学学报 (自然科学版), 2019,40(2): 167−172. SUN Y B, KONG H H, ZHANG Y X. Multi-energy spectral CT contrast agent material recognition based on projection domain decomposition[J]. Journal of North University of China (Natural Science Edition), 2019, 40(2): 167−172. (in Chinese).
[10] LI Z, RAVISHANKAR S, LONG Y, et al. Learned mixed material models for efficient clustering based dual-energy CT image decomposition[C]//2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP). IEEE, 2018: 529-533.
[11] 李磊. 双能CT图像重建算法研究[D]. 郑州: 解放军信息工程大学, 2016. LI L. Research on image reconstruction algorithms of dual energy computed tomography[D]. Zhengzhou: Information Engineering University, 2016. (in Chinese).
[12] MCCOLLOUGH C H, SCHMIDT B, LIU X, et al. Dual-energy algorithms and postprocessing techniques[M]//Dual energy CT in clinical practice. Springer, Berlin, Heidelberg, 2011: 43-51.
[13] RUTHERFORD R, PULLAN B, ISHERWOOD I. X-ray energies for effective atomic number determination[J]. Neuroradiology, 1976, 11(1): 23−28. doi: 10.1007/BF00327254
[14] NISHIMURA D G, MACOVSKI A, BRODY W R. Noise reduction methods for hybrid subtraction[J]. Medical Physics, 1984, 11(3): 259−265. doi: 10.1118/1.595501
[15] JOHNS P C, YAFFE M J. Theoretical optimization of dual-energy X-ray imaging with application to mammography[J]. Medical Physics, 1985, 12(3): 289−296. doi: 10.1118/1.595766
[16] KALENDER W A, KLOTZ E, KOSTARIDOU L. An algorithm for noise suppression in dual energy CT material density images[J]. IEEE Transactions on Medical Imaging, 1988, 7(3): 218−224. doi: 10.1109/42.7785
[17] HINSHAW D A, DOBBINS III J T. Recent progress in noise reduction and scatter correction in dual-energy imaging[C]//Medical Imaging 1995: Physics of Medical Imaging, SPIE, 1995, 2432: 134-142.
[18] WARP R J, DOBBINS J T. Quantitative evaluation of noise reduction strategies in dual-energy imaging[J]. Medical Physics, 2003, 30(2): 190−198. doi: 10.1118/1.1538232
[19] DONG X, NIU T, ZHU L. Combined iterative reconstruction and image-domain decomposition for dual energy CT using total-variation regularization[J]. Medical Physics, 2014, 41(5): 051909(1-9).
[20] ZHAO W, NIU T, XING L, et al. Using edge-preserving algorithm with non-local mean for significantly improved image-domain material decomposition in dual-energy CT[J]. Physics in Medicine & Biology, 2016, 61(3): 1332−1351.
[21] 陈佩君, 冯鹏, 伍伟文, 等. 基于图像总变分和张量字典的多能谱CT材料识别研究[J]. 光学学报, 2018, 38(11): 1111002(1-8). CHEN P J, FENG P, WU W W, et al. Material discrimination by multi-spectral CT based on lmage total variation and tensor dictionary[J]. Acta Optica Sinica 2018, 38(11): 1111002(1-8). (in Chinese).
[22] DENG G, CHEN M, HE P, et al. The experimental study on geometric calibration and material discrimination for in Vivo dual-energy CT imaging[J]. Biomedical Research International, 2019, 2019: 7614589.
[23] NIU T, DONG X, PETRONGOLO M, et al. Iterative image-domain decomposition for dual-energy CT[J]. Medical Physics, 2014, 41(4): 041901(1−10).
[24] TANG S, YANG M, HU X, et al. Multiscale penalized weighted least-squares image-domain decomposition for dual-energy CT[C]//2015 IEEE Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC). IEEE, 2015: 1-6.
[25] LI Z, RAVISHANKAR S, LONG Y, et al. DECT-MULTRA: Dual-energy CT image decomposition with learned mixed material models and efficient clustering[J]. IEEE Transactions on Medical Imaging, 2020, 39(4): 1223−1234. doi: 10.1109/TMI.2019.2946177
[26] 王冲旭, 陈平, 潘晋孝, 等. 基于迭代残差网络的双能CT图像材料分解研究[J]. CT理论与应用研究, 2022,31(1): 47−54. DOI: 10.15953/j.1004-4140.2022.31.01.05. WANG C X, CHEN P, PAN J X, et al. Research on material decomposition of dual-energy CT image based on iterative residual network[J]. CT Theory and Applications, 2022, 31(1): 47−54. DOI: 10.15953/j.1004-4140.2022.31.01.05. (in Chinese).
[27] XU Y, YAN B, ZHANG J, et al. Image decomposition algorithm for dual-energy computed tomography via fully convolutional network[J]. Computational and Mathematical Methods in Medicine, 2018, 2018(1): 2527516.
[28] 朱冬亮, 文奕, 陶欣. 深度学习在生物医学领域的应用进展述评[J]. 世界科技研究与发展, 2020,42(5): 510−519. ZHU D L, WEN Y, TAO X. A Review of the application progress of deep learning in biomedical field[J]. World Sci-Tech R & D, 2020, 42(5): 510−519. (in Chinese).
[29] KAWAHARA D, SAITO A, OZAWA S, et al. Image synthesis with deep convolutional generative adversarial networks for material decomposition in dual-energy CT from a kilovoltage CT[J]. Computers in Biology and Medicine, 2021, 128: 104111. doi: 10.1016/j.compbiomed.2020.104111
[30] LYU T, ZHAO W, ZHU Y, et al. Estimating dual-energy CT imaging from single-energy CT data with material decomposition convolutional neural network[J]. Medical Image Analysis, 2021, 70: 102001. doi: 10.1016/j.media.2021.102001
[31] CLARK D P, HOLBROOK M, BADEA C T. Multi-energy CT decomposition using convolutional neural networks[C]//Medical Imaging 2018: Physics of Medical Imaging. International Society for Optics and Photonics, 2018, 10573: 415-423.
[32] ZHANG W, ZHANG H, WANG L, et al. Image domain dual material decomposition for dual-energy CT using butterfly network[J]. Medical Physics, 2019, 46(5): 2037−2051. doi: 10.1002/mp.13489
[33] SHI Z, LI H, CAO Q, et al. A material decomposition method for dual-energy CT via dual interactive Wasserstein generative adversarial networks[J]. Medical Physics, 2021, 48(6): 2891−2905. doi: 10.1002/mp.14828
[34] 郭志鹏. Micro-CT重建图像质量增强的方法研究[D]. 西安: 西安电子科技大学, 2017. GUO Z P. Research on image quality enhancement method in micro-CT reconstruction[D]. Xi'an: Xidian University, 2017. (in Chinese).
[35] LIU X, YU L, PRIMAK A N, et al. Quantitative imaging of element composition and mass fraction using dual-energy CT: Three-material decomposition[J]. Medical Physics, 2009, 36(5): 1602−1609. doi: 10.1118/1.3097632
[36] MENDONÇA P R, LAMB P, SAHANI D V. A flexible method for multi-material decomposition of dual-energy CT images[J]. IEEE Transactions on Medical Imaging, 2014, 33(1): 99−116. doi: 10.1109/TMI.2013.2281719
[37] JIANG Y, XUE Y, LYU Q, et al. Noise suppression in image-domain multi-material decomposition for dual-energy CT[J]. IEEE Transactions on Biomedical Engineering, 2020, 67(2): 523−535. doi: 10.1109/TBME.2019.2916907
[38] LEE H, KIM H J, LEE D, et al. Improvement with the multi-material decomposition framework in dual-energy computed tomography: A phantom study[J]. Journal of the Korean Physical Society, 2020, 77(6): 515−523. doi: 10.3938/jkps.77.515
[39] 降俊汝, 余海军, 龚长城, 等. 基于双能CT图像域的DL-RTV多材料分解研究[J]. 光学学报, 2020,40(21): 2111004(1−12). JIANG J R, YU H J, GONG C C, et al. Image-domain multimaterial decomposition for dual-energy CT based on dictionary learning and relative total variation[J]. Acta Optica Sinica, 2020, 40(21): 2111004(1−12). (in Chinese).
[40] LONG Y, FESSLER J A. Multi-material decomposition using statistical image reconstruction for spectral CT[J]. IEEE Transactions on Medical Imaging, 2014, 33(8): 1614−1626. doi: 10.1109/TMI.2014.2320284
[41] XUE Y, RUAN R, HU X, et al. Statistical image-domain multimaterial decomposition for dual-energy CT[J]. Medical Physics, 2017, 44(3): 886−901. doi: 10.1002/mp.12096
[42] DING Q, NIU T, ZHANG X, et al. Image-domain multimaterial decomposition for dual-energy CT based on prior information of material images[J]. Medical Physics, 2018, 45(8): 3614−3626. doi: 10.1002/mp.13001
[43] PATINO M, PROCHOWSKI A, AGRAWAL M D, et al. Material separation using dual-energy CT: Current and emerging applications[J]. Radiographics, 2016, 36(4): 1087−1105. doi: 10.1148/rg.2016150220




























































计量
- 文章访问数: 2791
- HTML全文浏览量: 227
- PDF下载量: 247


