
Coherent Beam-forming Combined with Wiener Filter in Ultrasound Imaging
-
摘要: 传统超声动态聚焦通过简单的延时叠加方法成像,分辨率较低、对比度较差。本研究在基于像素的相干波束合成(Coherent PB)的基础上,应用一种计算效率较高的前置维纳滤波器,利用焦点处的脉冲回波对整个阵列信号进行相位矫正,并通过后置维纳滤波器为每次子孔径波束合成结果施加自适应权值,进一步抑制噪声和伪影。通过仿真、仿体和在体实验对本方法的有效性进行验证,与Coherent PB相比,本方法在保持较高横向分辨率和计算效率的基础上,明显改善图像的轴向分辨率和对比度,具有一定临床应用价值。Abstract: The traditional ultrasonic dynamic focusing imaging which simply uses the delay-and-sum method in beamforming shows low resolution and poor contrast. In this study, based on the coherent pixel-based beamforming (Coherent PB), a novel Wiener pre-filter with high computational efficiency is applied to correct the phase of the entire array signal by using the pulse-echo at the focal point. We also apply a Wiener post-filter calculating adaptive weights for the beamforming results of each sub-aperture to suppress the noise and artifacts. The proposed method's effectiveness is verified through simulation experiments, phantom experiments, and in vivo experiments. Compared with Coherent PB, the proposed method significantly improves the axial resolution and contrast of images while maintaining the high lateral resolution and computational efficiency, which shows certain clinical application value.
-
Keywords:
- ultrasound beamforming /
- coherent /
- Wiener filter /
- axial resolution
-
随着年龄的增长,腰椎退行性变及椎间盘病变日趋增多,CT检查能及时发现诊断腰椎病变并能随访治疗效果,但CT检查辐射问题一直为人们所关注,随着患者受辐射剂量的增加,癌症的发生概率会增大,腰椎CT扫描范围包括性腺,而人体性腺对辐射最敏感,所以开展低剂量腰椎CT检查非常必要。
以往研究均是通过降低管电压或者降低管电流来降低辐射剂量,因腰椎体层较厚,降低管电压或管电流会导致图像噪声增加。本文为解决腰椎CT高辐射剂量及图像噪声偏高的问题,采用最新的能谱纯化技术结合高级模拟迭代重建(ADMIRE)技术,探讨如何更好的优化腰椎CT检查的图像质量和降低辐射剂量。
1. 材料与方法
1.1 一般资料
选取2021年8月至2022年5月因腰痛来我院行腰椎CT检查的患者,在检查前计算患者的体质量指数(bodymassindex,BMI),BMI=体重(kg)/身高(m)2。纳入年龄在25~65岁,BMI在18.5~25 kg/m2的患者,排除有腰椎手术史和腰椎畸形及有椎体金属植入物的患者,共收集88例。对照组(A组)、试验组(B组)每组44例。
A组与B组平均年龄分别为(45.9±12.1)岁和(47.2±13.8)岁。两组间年龄差异无统计学意义,A组与B组平均BMI分别为(20.1±2.89)kg/m2和(21.40±3.50)kg/m2。
1.2 扫描方法
采用德国SOMATOM Force第3代双源CT,扫描范围从胸12椎体至骶1椎体。扫描参数:对照组(A组)管电压120 kV,参考管电流350 mAs;试验组(B组)管电压Sn 150 kV,参考管电流350 mAs,其他扫描参数均一致。
重建采用高级模拟迭代重建算法(ADMIRE),重建等级3级,重建薄层图像,层厚1 mm,层间距0.60 mm,软组织窗采用软组织算法,卷积核Br40,骨窗采用骨算法,卷积核Br64,重建图像窗宽,窗位分别为350 HU和50 HU(软组织窗)、2500 HU和800 HU(骨窗)。所有图像重建完成后自动发至西门子Syngovia VB20A后处理工作站。
1.3 图像质量评价
1.3.1 客观评价
由1名主管技师从工作站中取L3椎体正中层面,在软组织窗上测量腰大肌与竖脊肌的CT值和噪声,腰大肌的噪声为SD1,竖脊肌的噪声为SD2,噪声值用对应所测的标准差表示,并计算信噪比(SNR):
$$ {\rm{SNR}}=腰大肌\;{\rm{CT}}\;值/{\rm{SD}}1。$$ (1) 1.3.2 主观评价
由3名副主任及以上诊断医师双盲法进行评分。评价L3/4层面椎间盘、椎间孔、黄韧带、硬膜囊及小关节图像质量。评价标准[1]:2分(软组织结构清晰,其边缘清楚,无伪影,且诊断明确);1分(软组织结构清晰,边缘欠清,有轻度伪影,但尚可诊断);0分(软组织结构不清,边缘模糊,伪影较重,不能进行诊断)。
1.4 辐射剂量
统计设备记录的容积CT剂量指数(CT dose index volumes,CTDIvol)及剂量长度乘积(dose length product,DLP),并计算有效辐射剂量(effective dose,ED)[2],计算公式:
$$ {\rm{ED}}={\rm{DLP}}\times k(k=0.011\;{\rm{mSv}}\cdot{\rm{mGy}}\cdot{\rm{cm}})。$$ (2) 1.5 统计学分析
1.5.1 客观评价和辐射剂量统计分析
采用SPSS 26.0软件对数据进行统计学分析。连续性数据非正态分布数据两组间比较采用Mann-Whitney U检验,用中位数及四分位数(M(Q25,Q75))表示。双侧检验,以P<0.05为差异有统计学意义。
1.5.2 主观评价
采用组内相关系数(intraclass correlation coefficient,ICC)对3位诊断医师的评分结果一致性进行分析。ICC介于0和1之间,ICC大于0.75表示一致性较好。
2. 结果
2.1 客观评价结果
两组图像腰大肌的CT值、竖脊肌的CT值和噪声(SD2)、SNR均存在统计学差异,而腰大肌的噪声(SD1)不具有统计学差异(表1);图1为120 kV轴位上噪声和CT值测量及矢状位重组图,图2为Sn 150 kV下的轴位上噪声和CT值测量测量及矢状位重组图。
表 1 A组和B组图像质量客观评价表Table 1. Objective evaluation of image quality in groups A and B项目 组别 统计检验 A组 B组 Z P 腰大肌/HU 53.00(48.70~56.00) 47.90(43.70~51.00) 2.741 0.016 SD1 5.73(4.83~6.83) 5.09(4.69~5.24) 1.904 0.057 竖脊肌/HU 52.00(46.2~55.00) 43.50(38.20~51) 3.511 <0.001 SD2 5.41(5.27~5.98) 4.56(3.62~5.63) 3.964 <0.001 SNR 9.12(7.88~10.51) 9.86(7.95~10.02) -0.693 0.488 ![]() 图 1 管电压120 kV下CT值和噪声测量及矢状位重组图(重组层厚1 mm、间隔0.6 mm)Figure 1. CT value, noise measurement, and sagittal position recombination at 120 kV tube voltage (recombination layer thickness 1 mm, interval 0.6 mm)
图 1 管电压120 kV下CT值和噪声测量及矢状位重组图(重组层厚1 mm、间隔0.6 mm)Figure 1. CT value, noise measurement, and sagittal position recombination at 120 kV tube voltage (recombination layer thickness 1 mm, interval 0.6 mm)![]() 图 2 管电压Sn 150 kV下CT值和噪声测量及矢状位重组图(重组层厚1 mm、间隔0.6 mm)Figure 2. CT value, noise measurement, and sagittal position recombination at tube voltage Sn 150 kV (recombination layer thickness 1 mm, interval 0.6 mm)
图 2 管电压Sn 150 kV下CT值和噪声测量及矢状位重组图(重组层厚1 mm、间隔0.6 mm)Figure 2. CT value, noise measurement, and sagittal position recombination at tube voltage Sn 150 kV (recombination layer thickness 1 mm, interval 0.6 mm)2.2 主观评价
3位医师对椎间盘、椎间孔、黄韧带、硬膜囊及小关节及整体图像质量评价均无统计学差异(表2),说明两组图像质量医师主观评价无差异,且均能符合医师诊断要求。
表 2 3位诊断医师的主观评分统计分析表Table 2. Statistical analysis of the subjective scores from the three doctors interpreting the computed tomography images指标 组别 P A组 B组 椎间盘 2.00±0.00 2.00±0.00 >0.999 椎间孔 1.98±0.15 1.98±0.15 0.156 黄韧带 1.95±0.21 2.00±0.00 0.562 硬膜囊 1.98±0.15 1.95±0.21 >0.999 小关节图像 2.00±0.00 2.00±0.00 0.320 整体图像质量 2.00±0.00 2.00±0.00 >0.999 2.3 辐射剂量
两组辐射剂量DLP、ED有统计学差异,两组辐射剂量差异明显,B组DLP值比A组降低了32.27%,B组ED值比A组降低了30.31%(表3)。
表 3 A组和B组辐射剂量统计表Table 3. Radiation dose in groups A and B项目 组别 统计检验 A组 B组 Z P mAs 333.00(300.00~362.00) 237.50(222.00~261.00) 7.885 <0.001 CTDIvol 14.75(13.65~16.00) 6.57(5.20~7.23) 8.015 <0.001 DLP 413.60(351.00~425.50) 280.13(230.89~327.20) 6.946 <0.001 ED 4.55(3.86~4.68) 3.08(2.54~3.60) 6.946 <0.001 3. 讨论
腰椎因体层相对较厚,需要高管电压来增加X线的穿透力,高管电流来降低图像的噪声,造成腰椎CT辐射剂量往往较高,以往研究都是通过降低管电流来降低辐射剂量。随着设备和技术的进步,众多新的降低辐射剂量的技术出现,如:低管电压[3-4]、自动管电流[5-6]、高级迭代重建算法[7]、能谱纯化[8]等,这些技术为我们开展低剂量CT提供了条件。
本研究B组管电压是用能谱纯化Sn 150 kV,而A组管电压是用120 kV,统计结果显示B组的辐射剂量低于A组30.31%。因为A组120 kV的X线球管是用铜和铝滤过,Sn 150 kV的X线球管是用能谱纯化技术的锡滤过,锡的原子序数比铜和铝高,锡滤过板能过滤掉X线球管的低能级射线,提高射线能量,而对人体产生辐射的主要是低能级软射线,低能级软射线以光电效应为主,大部分被人体吸收产生辐射。能谱纯化技术只保留了对人体成像有用的高能级射线,高能级射线会穿过人体相对辐射较少,所以B组辐射剂量低于A组,多学者也证实了这一说法[9-13]。
客观评价中A组肌肉的噪声要高于B组,腰大肌的噪声两组之间无统计学差异,而竖脊肌的噪声两组之间有统计学差异,此结果说明射线能量和图像噪声成正相关,也证实了Sn 150 kV的穿透力较120 kV的好。因竖脊肌处于腰大肌的下层,射线先穿过腰大肌再到竖脊肌,射线能量会因组织的阻挡发生衰减,A组射线的能量到达竖脊肌时比B组衰减更多,因衰减后的能量差异造成了噪声值的差异,故造成了两组不同肌肉之间统计学结果的差异。
沈梓璇等[14]论述了120 kVp管电压所获得的腰椎图像质量评分以及信噪比皆较高,但辐射剂量也较大的观点。本文为了解决这一问题,首次采用Sn 150 kV用于腰椎CT检查,主观评价结果显示,3位观察者的ICC为0.829,表示为两组图像主观评价一致性较好,说明两组图像质量均满足诊断要求,主客观评价结果均证实了Sn 150 kV用于腰椎CT检查是可行的。王帅等[15]也证实Sn 150 kV能用于全腹部CT检查,且辐射剂量较低,与本文研究结果一致。
高级模拟迭代重建,是将原始图像中的原始数据噪声投射到图像中,得到的图像是多次迭代重建后的组合,再将原始数据进行准确的图像校正,对原始数据域进行去噪及去除伪影,最后进行图像域的校正,反复迭代来降低噪声,图像空间分辨率不受影响。客观评价表中A组和B组图像的噪声均值都处于10以下,证实了高级模拟迭代重建的降噪能力。顾海峰等[16]和Schlunk等[17]也证明了迭代重建能降低噪声保证图像质量满足诊断需求。
综上所述,采用能谱纯化Sn 150 kV结合ADMIRE,不但能有效减低辐射剂量,还可保证优质的图像质量,值得在成人腰椎CT中推广使用。
-
![]()
图 1 双脉冲模型原理图
(a)根据Verasonics Vantage-256的参数,用Field Ⅱ模拟的发射场模式及施加变迹示意图。(b)在成像点P1、P2、P3和焦点F处产生的发射波形。所有波形都被归一化为在P2处模拟的振幅[11]。
Figure 1. Schematic diagram of two-pulse characterization model
![]()
图 3 仿真实验结果图
其中包含6个散射点目标和1个在随机背景中的低回声囊肿。散射点呈八字状分布在深度22 mm、25 mm和28 mm处。囊肿的直径为5 mm,中心在(z, x)=(25, 3) mm。图像是使用Dynamic focusing、Coherent PB、CWF-PB、CWF-ScW 4个波束合成器生成的,采用对数压缩,动态显示范围为70 dB。
Figure 3. Results of simulation experiments
![]()
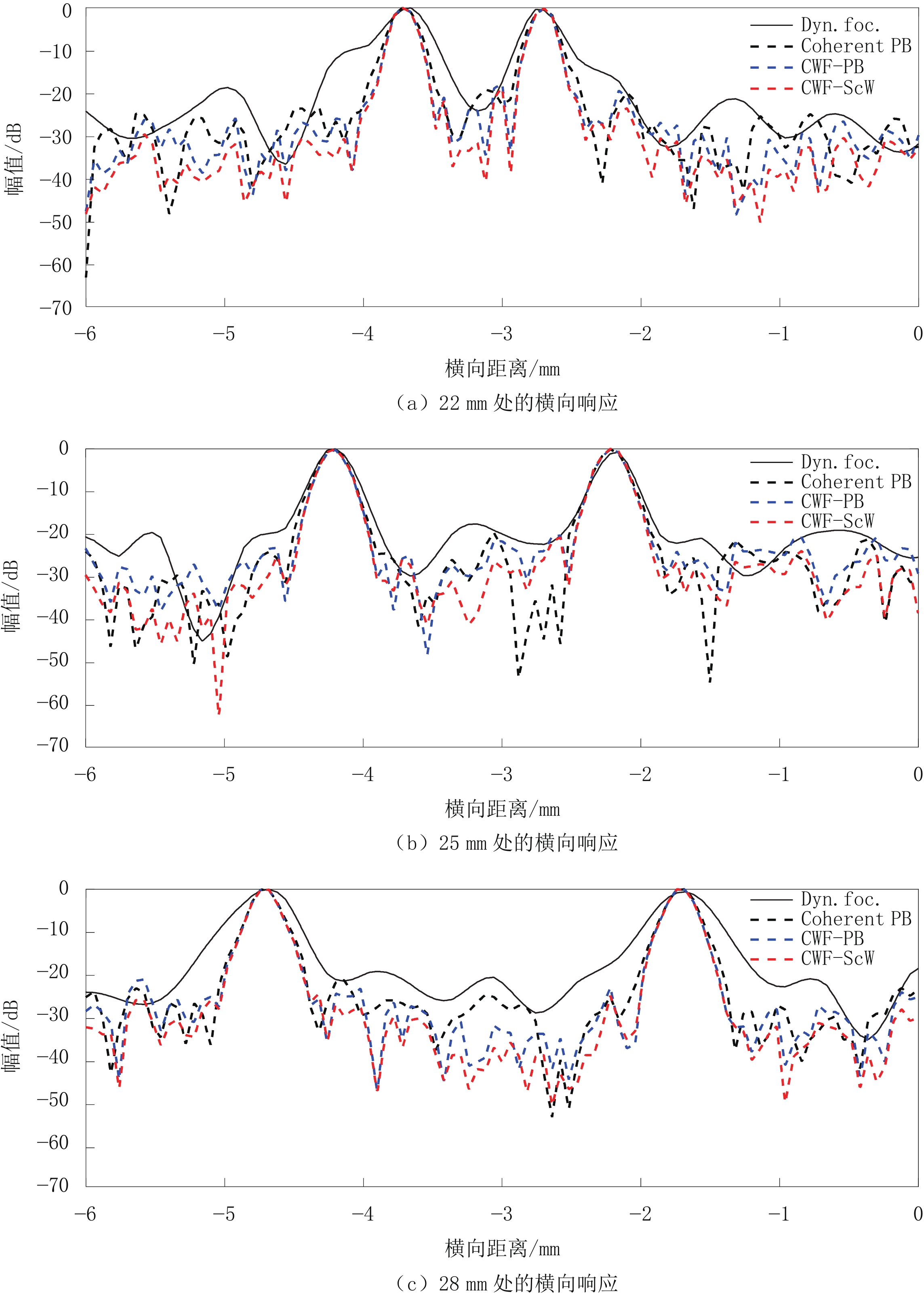
图 4 仿真实验中3个深度处的点目标的波束横向剖面图
图像是使用Dynamic focusing、Coherent PB、CWF-PB、CWF-ScW 4个波束合成器生成的。
Figure 4. Transverse cross-sections of beams at 3 depths in simulation experiments
![]()
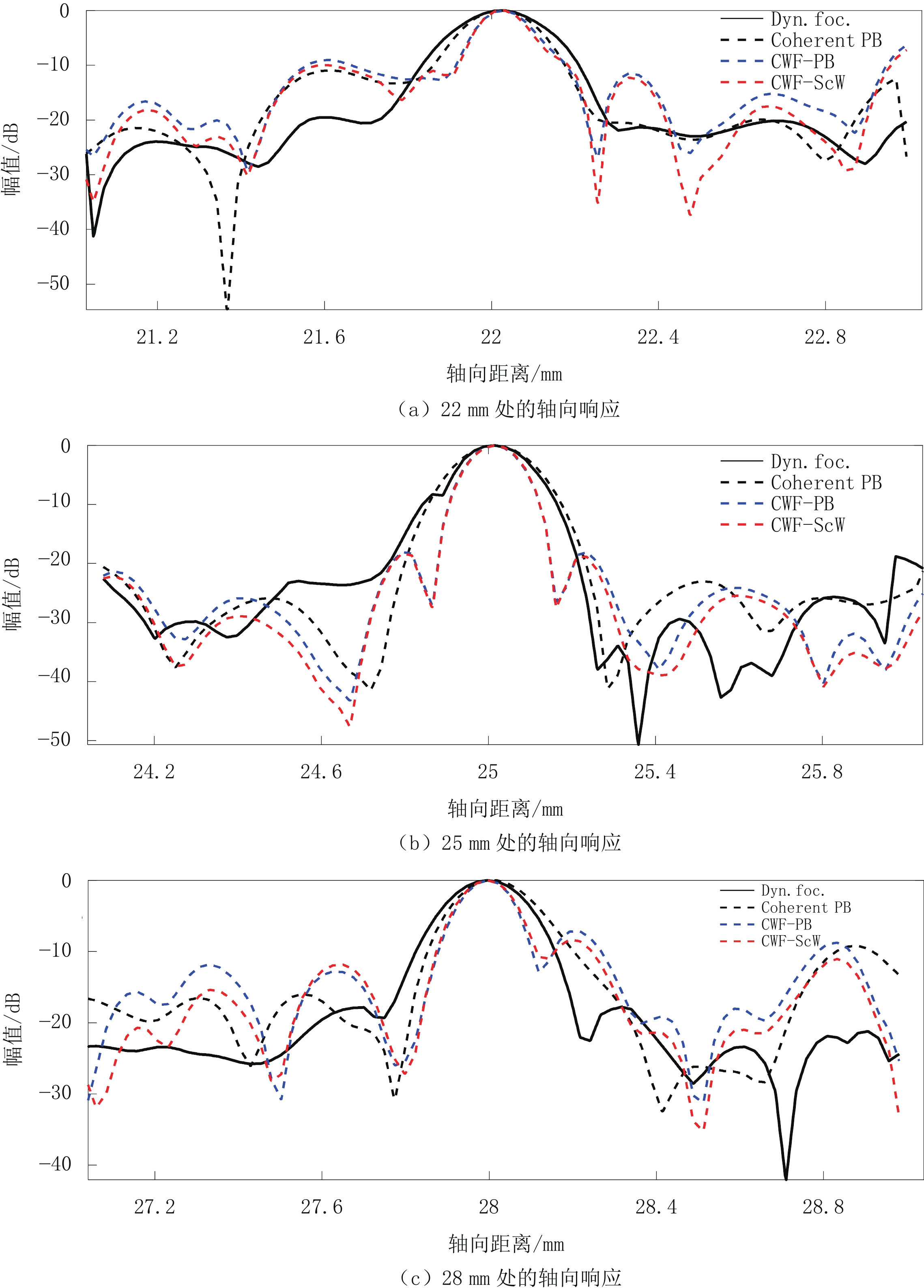
图 5 仿真实验中3个深度处的点目标的波束轴向剖面图
图像是使用Dynamic focusing、Coherent PB、CWF-PB、CWF-ScW 4个波束合成器生成的。
Figure 5. Transverse axial-sections of beams at 3 depths in simulation experiments
![]()
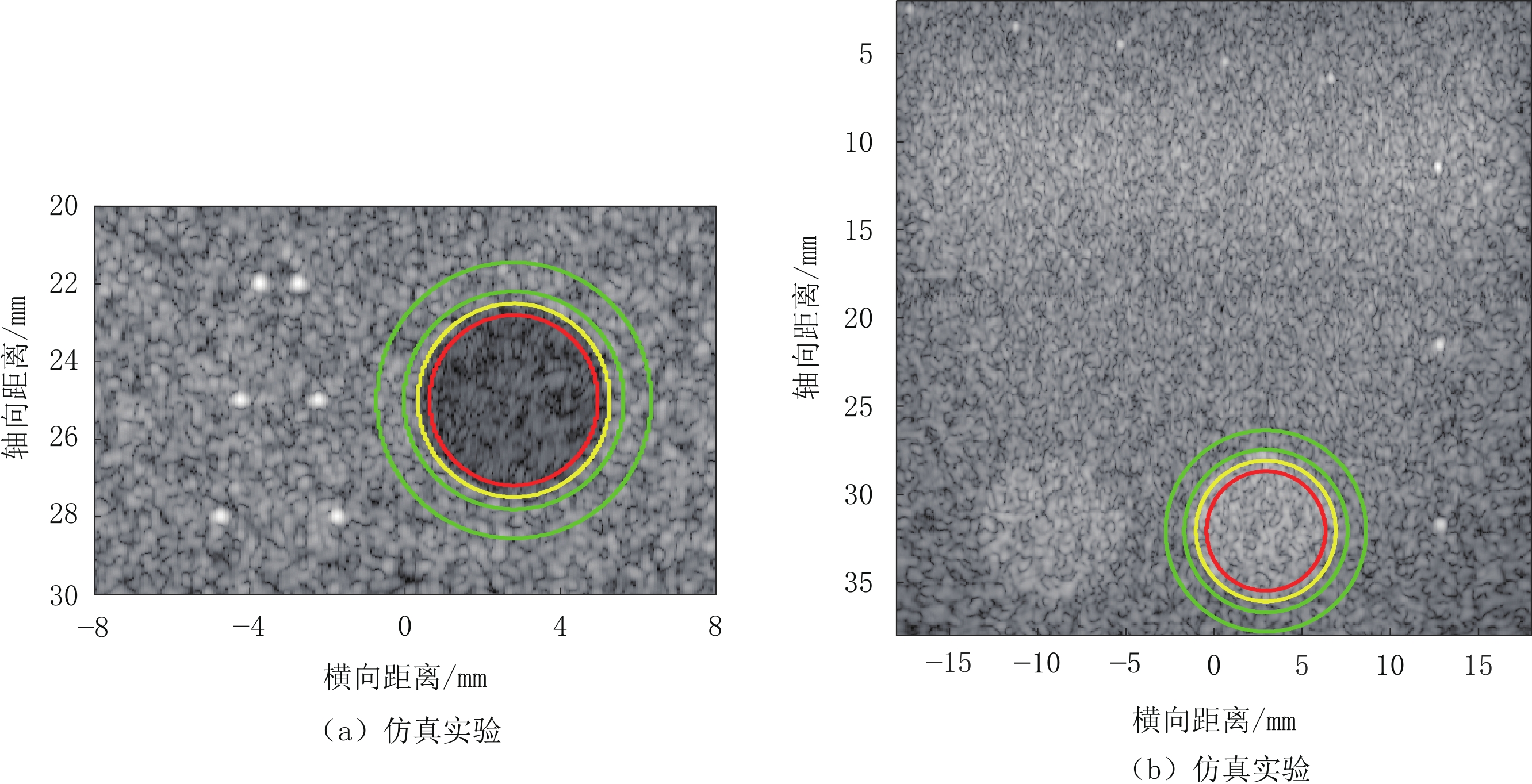
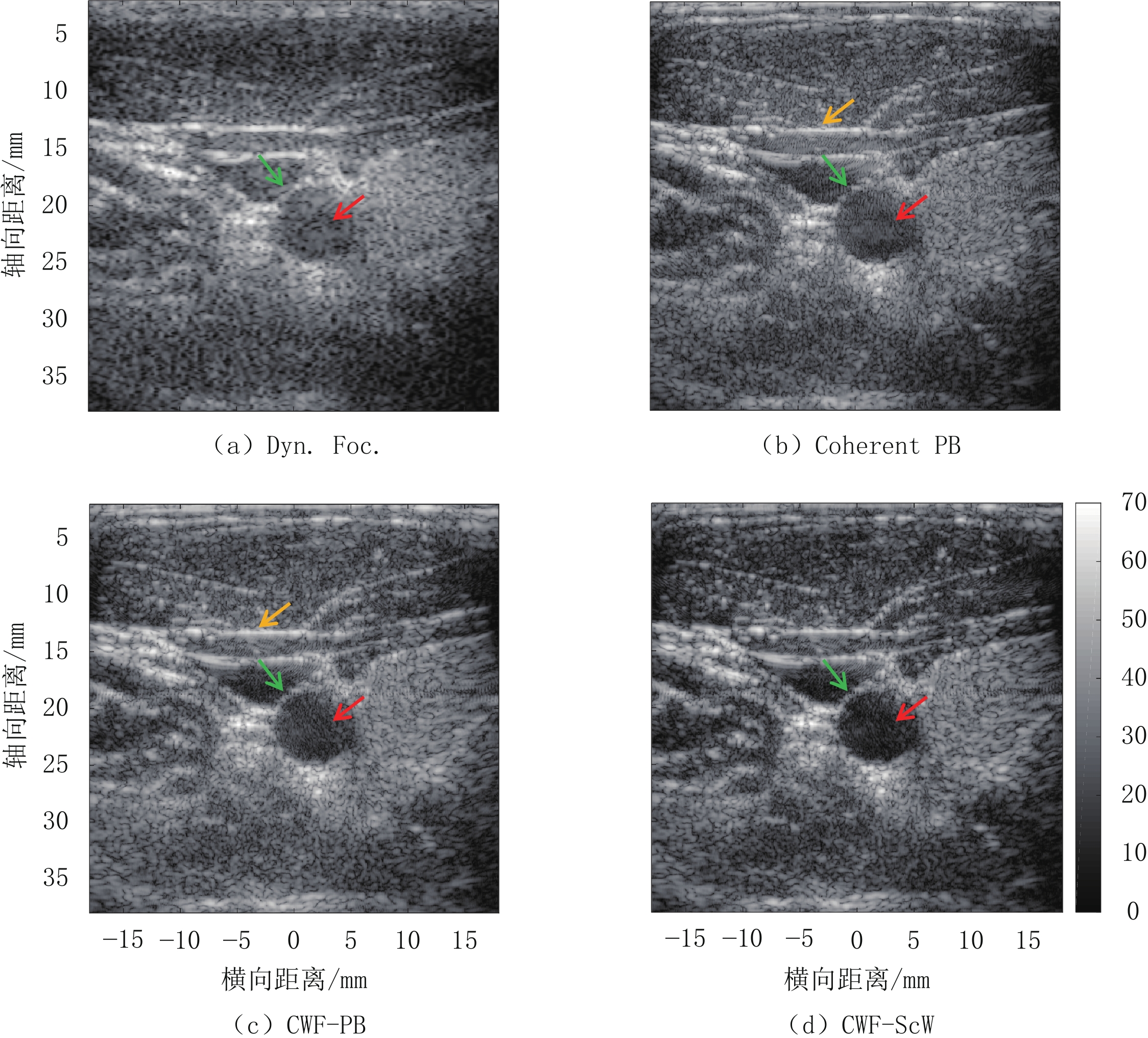
图 6 仿体实验结果图
其中包含2个高回声圆形目标及若干点目标。图像是使用Dynamic focusing、Coherent PB、CWF-PB、CWF-ScW 4个波束合成器生成的,采用对数压缩,动态显示范围为70 dB。
Figure 6. Results of phantom experiments
![]()
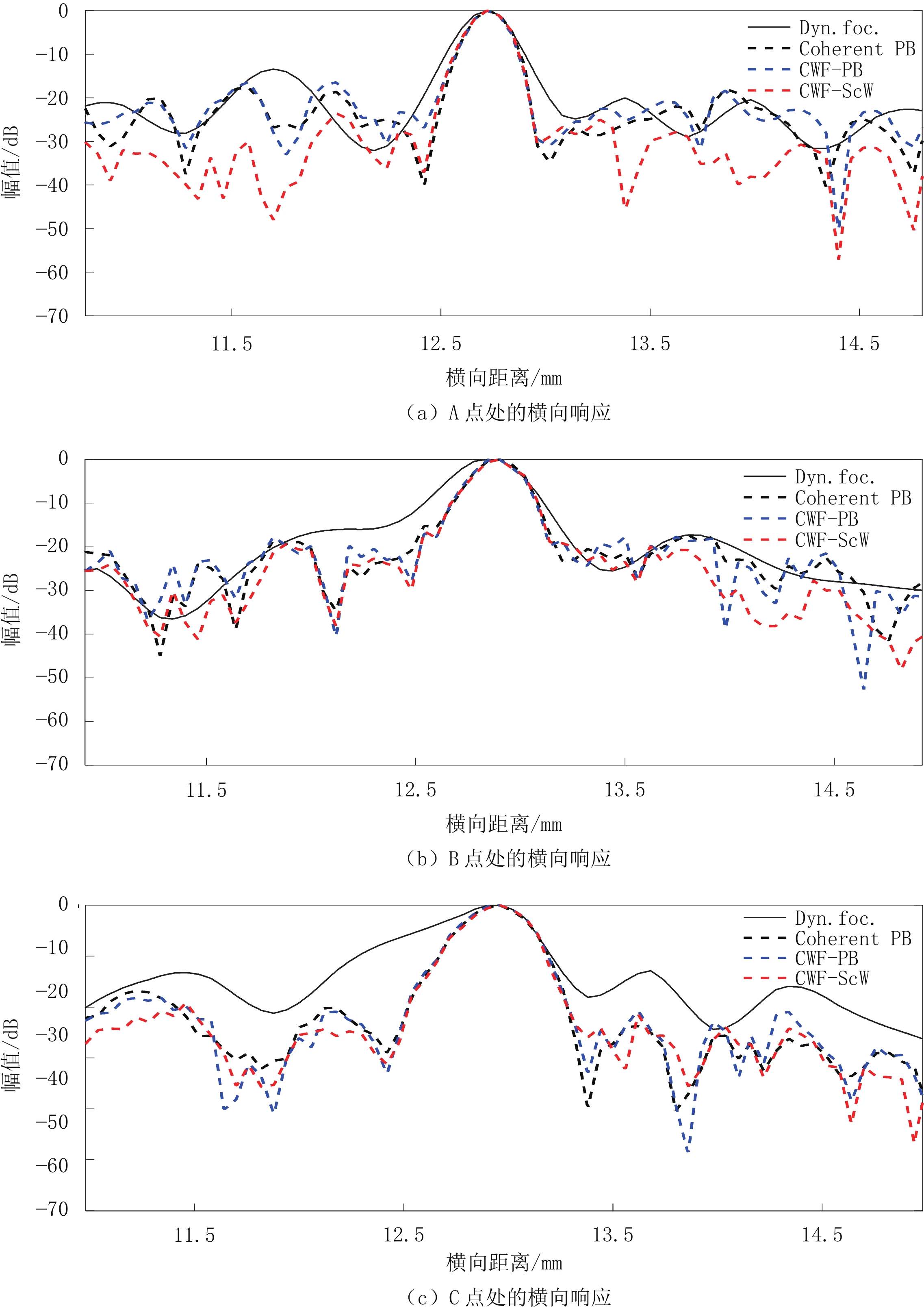
图 7 仿体实验中3个深度处的点目标的波束横向剖面图
图像是使用Dynamic focusing、Coherent PB、CWF-PB、CWF-ScW 4个波束合成器生成的。
Figure 7. Transverse cross-sections of beams at 3 depths in phantom experiments
![]()
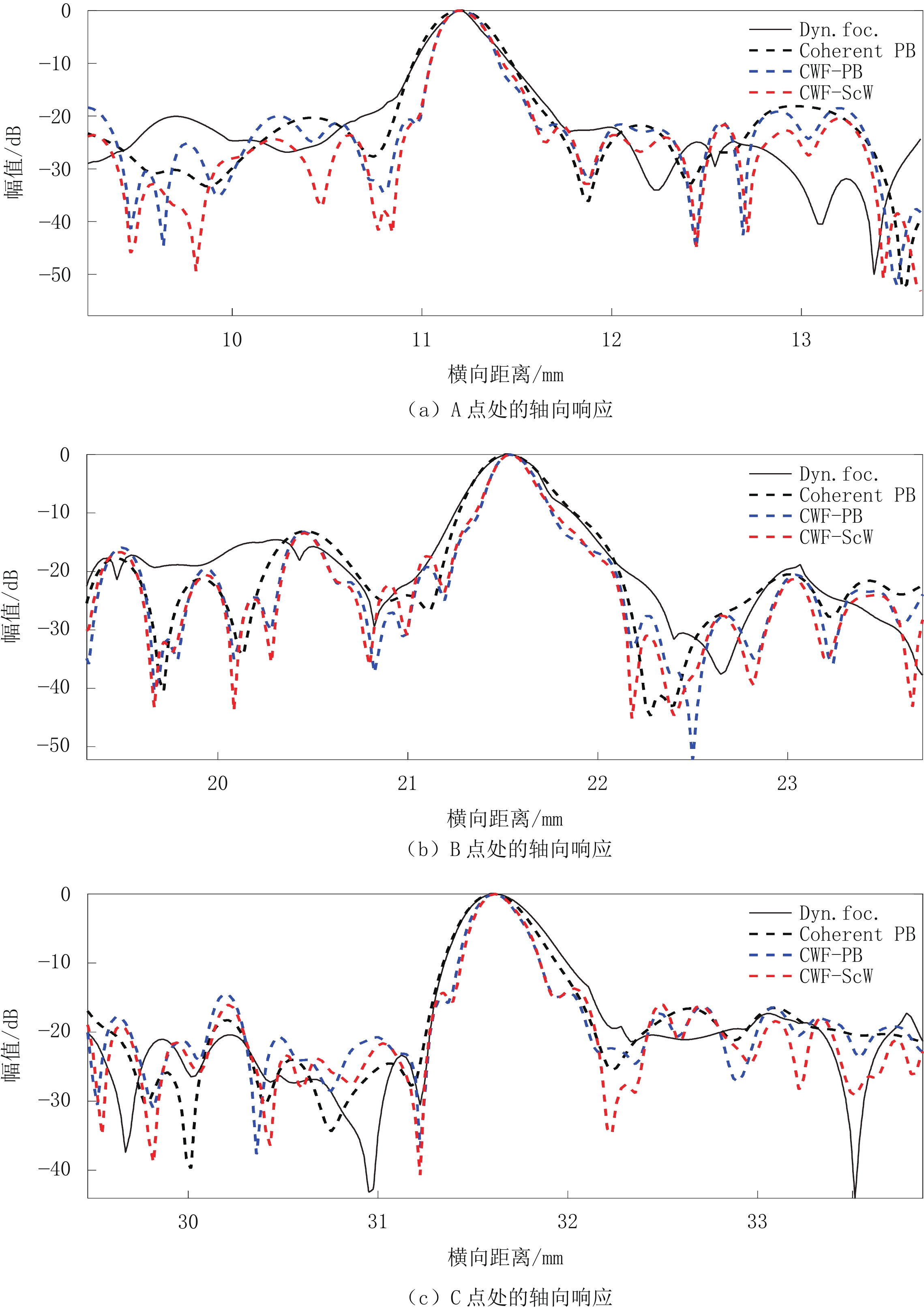
图 8 仿体实验中3个深度处的点目标的波束轴向剖面图
图像是使用Dynamic focusing、Coherent PB、CWF-PB、CWF-ScW 4个波束合成器生成的。
Figure 8. Transverse axial-sections of beams at 3 depths in phantom experiments
![]()
图 9 在体实验结果图
扫描部位为人体颈动脉。图像是使用Dynamic focusing、Coherent PB、CWF-PB、CWF-ScW 4个波束合成器生成的,采用对数压缩,采用对数压缩,动态显示范围为70 dB。
Figure 9. Results of in vivo experiment
表 1 仿真实验的分辨率及对比度
Table 1 Resolution and contrast of simulation experiments
波束合成器 横向FWHM位于/mm 轴向FWHM位于/mm CR CNR 22 25 28 22 25 28 Dyn. foc. 0.228 0.443 0.533 0.307 0.292 0.307 0.208 1.306 Coherent PB 0.234 0.264 0.276 0.239 0.249 0.263 0.333 1.799 CWF-PB 0.198 0.258 0.258 0.183 0.173 0.175 0.189 1.067 CWF-ScW 0.198 0.258 0.258 0.168 0.173 0.185 0.298 1.385  下载: 导出CSV
下载: 导出CSV
表 2 仿体实验的分辨率及对比度
Table 2 Resolution and contrast of phantom experiments
波束合成器 横向FWHM位于 轴向FWHM位于 CR CNR A点 B点 C点 A点 B点 C点 Dyn. foc. 0.276 0.413 0.629 0.347 0.410 0.484 0.141 0.871 Coherent PB 0.234 0.306 0.401 0.401 0.437 0.447 0.147 1.015 CWF-PB 0.228 0.306 0.420 0.288 0.286 0.337 0.148 1.005 CWF-ScW 0.240 0.300 0.407 0.296 0.278 0.330 0.187 1.147
下载: 导出CSV
-
[1] 郑驰超, 彭虎. 基于编码发射与自适应波束形成的超声成像[J]. 电子与信息学报, 2010,32(4): 959−962. ZHENG C C, PENG H. Ultrasounic imaging based on coded exciting technology and adaptive beamforming[J]. Journal of Electronics & Information Technology, 2010, 32(4): 959−962. (in Chinese).
[2] JENSEN J A, NIKOLOV S I, GAMMELMARK K L, et al. Synthetic aperture ultrasound imaging[J]. Ultrasonics, 2006, 44(8): e5−e15.
[3] NOWICKI A, GAMBIN B. Ultrasonic synthetic apertures: Review[J]. Archives of Acoustics, 2014, 39(4): 427−438.
[4] 孙宝申, 沈建中. 合成孔径聚焦超声成像(一)[J]. 应用声学: 1993, 12(3): 43-48. [5] 孙宝申, 张凡, 沈建中. 合成孔径聚焦声成像时域算法研究[J]. 声学学报, 1997,22(1): 42−49. SUN B S, ZHANG F, SHEN J Z. Synthetic aperture focusing in time-domain for acoustic imaging[J]. Acta Acustica, 1997, 22(1): 42−49. (in Chinese).
[6] 杜英华, 张聪颖, 陈世莉, 等. 合成孔径聚焦超声成像方法研究[J]. 海洋技术, 2010,29(2): 94−96. doi: 10.3969/j.issn.1003-2029.2010.02.023 DU Y H, ZHANG C Y, CHEN S L, et al. Research of synthetic aperture focus technology in ultrasonic imaging[J]. Ocean Technology, 2010, 29(2): 94−96. (in Chinese). doi: 10.3969/j.issn.1003-2029.2010.02.023
[7] 李遥, 吴文焘, 李平. 虚拟源方法应用于B超成像系统的研究[J]. 声学技术, 2013,32(S1): 183−184. LI Y, WU W T, LI P. A study of B-mode ultrasound imaging with virtual source method[J]. Technical Acoustics, 2013, 32(S1): 183−184. (in Chinese).
[8] 李瑶, 吴文焘, 李平. 超声虚源成像中自适应双向空间逐点聚焦方法[J]. 声学学报, 2016,41(3): 287−295. LI Y, WU W T, LI P. Adaptive bi-directional point-wise focusing method in ultrasonic imaging based on virtual source[J]. Acta Acustica, 2016, 41(3): 287−295. (in Chinese).
[9] FRAZIER C H, O'BRIEN W D. Synthetic aperture techniques with a virtual source element[J]. IEEE Transactions on Ultrasonics Ferroelectrics & Frequency Control, 1998, 45(1): 196−207.
[10] NGUYEN N Q, PRAGER R W. High-resolution ultrasound imaging with unified pixel-based beamforming[J]. IEEE Transactions on Biomedical Engineering, 2015, 35(1): 98−108.
[11] NGUYEN N Q, PRAGER R W. Ultrasound pixel-based beamforming with phase alignments of focused beams[J]. IEEE Transactions on Ultrasonics Ferroelectrics and Frequency Control, 2017, 64(6): 937−946. doi: 10.1109/TUFFC.2017.2685198
[12] KIM C, YOON C, PARK J H, et al. Evaluation of ultrasound synthetic aperture imaging using bidirectional pixel-based focusing: Preliminary phantom and in vivo breast study[J]. IEEE Transactions on Biomedical Engineering, 2013, 60(10): 2716−2724. doi: 10.1109/TBME.2013.2263310
[13] JENSEN J A, GORI P. Spatial filters for focusing ultrasound images[C]//2001 IEEE Ultrasonics Symposium Proceedings, 2001, 2: 1507-1511.
[14] 聂昕, 郭志福, 何智成, 等. 基于盲反卷积和参数化模型的超声参数估计[J]. 仪器仪表学报, 2015,36(11): 2611−2616. doi: 10.3969/j.issn.0254-3087.2015.11.027 NIE X, GUO Z F, HE Z C, et al. Parameters estimation of ultrasonic echo signal based on blind deconvolution and parameterized model[J]. Chinese Journal of Scientific Instrument, 2015, 36(11): 2611−2616. (in Chinese). doi: 10.3969/j.issn.0254-3087.2015.11.027
[15] 孔垂硕, 罗林, 李金龙, 等. 基于盲反卷积的超声合成孔径图像复原[J]. 电子制作, 2018,(7): 92−94. doi: 10.3969/j.issn.1006-5059.2018.07.035 [16] KIM K S, LIU J, INSANA M F. Efficient array beam forming by spatial filtering for ultrasound B-mode imaging[J]. Journal of the Acoustical Society of America, 2006, 120(2): 852. doi: 10.1121/1.2214393
[17] XIE H W, GUO H, ZHOU G Q, et al. Improved ultrasound image quality with pixel-based beamforming using a Wiener-filter and a SNR-dependent coherence factor[J]. Ultrasonics, 2022, 119: 106594. doi: 10.1016/j.ultras.2021.106594
[18] MALLART R, FINK M. Adaptive focusing in scattering media through sound-speed inhomogeneities: The van cittert zernike approach and focusing criterion[J]. The Journal of the Acoustical Society of America, 1994, 96(6): 3721−3732. doi: 10.1121/1.410562
[19] LI P C, LI M L. Adaptive imaging using the generalized coherence factor[J]. IEEE Transactions on Ultrasonics Ferroelectrics and Frequency Control, 2003, 50(2): 128−141. doi: 10.1109/TUFFC.2003.1182117
[20] CAMACHO J, PARRILLA M, FRITSCH C. Phase coherence imaging[J]. IEEE Transactions on Ultrasonics Ferroelectrics and Frequency Control, 2009, 56(5): 958−974. doi: 10.1109/TUFFC.2009.1128
[21] NILSEN C I C, HOLM S. Wiener beamforming and the coherence factor in ultrasound imaging[J]. Ultrasonics Ferroelectrics & Frequency Control IEEE Transactions on, 2010, 57(6): 1329−1346.
[22] JENSEN J A, SVENDSEN N B. Calculation of pressure fields from arbitrarily shaped, apodized, and excited ultrasound transducers[J]. Ultrasonics, Ferroelectrics and Frequency Control, IEEE Transactions on, 1992, 39(2): 262−267. doi: 10.1109/58.139123
[23] COBBOLD R S C. Foundations of biomedical ultrasound[J]. Foundations of Biomedical Ultrasound, 2006.
[24] ALIABADI S, WANG Y, YU J. Adaptive scaled Wiener postfilter beamformer for ultrasound imaging[C]//2016 URSI Asia-Pacific Radio Science Conference (URSI AP-RASC), 2016: 1449-1452.
[25] 郭建中, 林书玉. 超声检测中维纳逆滤波解卷积方法的改进研究[J]. 应用声学, 2005,24(2): 97−102. doi: 10.3969/j.issn.1000-310X.2005.02.007 GUO J Z, LIN S Y. A modified Wiener inverse filter for deconvolution in ultrasonic detection[J]. Applied Acoustics, 2005, 24(2): 97−102. (in Chinese). doi: 10.3969/j.issn.1000-310X.2005.02.007
[26] 李静, 乔建民, 王俊奇, 等. 心外膜及心周脂肪体积与颈动脉粥样斑块的关系[J]. CT理论与应用研究, 2017,26(6): 761−768. DOI: 10.15953/j.1004-4140.2017.26.06.13. LI J, QIAO J M, WANG J Q, et al. Correlation of epicardial adipose tissue and pericardial adipose tissue with carotid artery plaque[J]. CT Theory and Application, 2017, 26(6): 761−768. DOI: 10.15953/j.1004-4140.2017.26.06.13. (in Chinese).
-
期刊类型引用(2)
1. 涂立冬,李雅萍. 岩土勘查技术在盐矿绿色矿山建设中的应用初探. 盐科学与化工. 2025(04): 9-12 .  百度学术
百度学术
2. 杨兆林,潘懿,白旭晨,刘禄平. 露天铁矿采空区隐蔽致灾普查与防治措施应用研究. 矿业研究与开发. 2024(09): 74-81 . 百度学术
其他类型引用(2)







计量
- 文章访问数: 540
- HTML全文浏览量: 343
- PDF下载量: 223
- 被引次数: 4
