
Automatic Identification of Relationship between Tooth Root and Mandibular Canal Based on One Step Deep Neural Network
-
摘要: 为了提高曲面体层片中下颌阻生智齿牙根与下颌管位置关系的识别精度和效率,提出一种基于深度卷积神经网络的自动检测方法。该方法将下颌阻生智齿牙根与下颌管位置关系的自动检测视为回归任务与分类任务的结合,以YOLOv5网络为框架构建可同时完成分类和定位任务的深度卷积神经网络,将对应锥形束CT图像中获取的空间位置关系信息作为分类金标准,训练其学习曲面体层片图像特征与接触下颌管的智齿牙根之间的非线性关系。将新获得的曲面体层片输入到训练好的网络模型后,即可获得该曲面体层片下颌阻生智齿牙根与下颌管相互接触的概率值,同时预测出存在牙根与下颌管相互接触情况的区域。实验结果表明,本文方法能准确地判断出下颌阻生智齿牙根与下颌管是否接触,并能预测出存在牙根与下颌管相互接触情况的区域;与人工判读和其他方法相比,能获得更准确的检测结果。Abstract: To improve the accuracy and efficiency of identifying the relationship between the root of the impacted mandibular third molar (M3M) and the mandibular canal in panoramic radiographs, we proposed an automatic method based on a deep convolutional neural network. This method treats the automatic identification of the relationship between the root of the M3M and the mandibular canal as a combination of regression and classification tasks. It uses the YOLOv5 (You Only Look Once) network as a framework for constructing a deep convolutional neural network that can accomplish detection and classification tasks simultaneously. This network, which takes the spatial relationship information extracted from the corresponding cone-beam CT images as the ground-truth, was trained to learn the nonlinear relationship between image features and the root of the M3M contacting the mandibular canal. When inputting a newly acquired panoramic radiograph into the trained network, the network will output the probability value for the root of the M3M contacting the mandibular canal. In the meantime, the region that includes the root of the M3M contacting the mandibular canal can be predicted. The experimental results show that the proposed method can provide an accurate judgment of whether the roots of impacted mandibular wisdom teeth in the panoramic radiographs are in contact with the mandibular canal and the location of regions in which the roots of the M3M are in contact with the mandibular canals; compared to manual diagnosis and the other methods, the proposed method can obtain more accurate results.
-
口腔临床通常将下颌阻生智齿牙根与下颌管的位置关系分为邻近、接触和重叠3类,其中邻近关系表明下颌阻生智齿的牙根未与下颌管接触;接触关系表明下颌阻生智齿的牙根与下颌管上壁接触;重叠关系表明下颌阻生智齿的牙根不仅和下颌管上壁接触,甚至越过下颌管上壁。术前准确判断下颌阻生智齿牙根与下颌管位置关系,是评估拔除智齿手术后是否会对下牙槽神经管造成损伤的重要依据[1]。
临床医生常通过锥形束CT(cone-beam computed tomography,CBCT)图像和曲面体层片来诊断下颌阻生智齿牙根与下颌管的位置关系。由于曲面体层图像存在解剖结构相互重叠、缺乏颊舌向信息等固有的成像缺点,通过CBCT图像判断下颌阻生智齿牙根与下颌管位置关系的准确率比曲面体层图像更高,但是CBCT图像的采集过程伴随着较高的电离辐射剂量,可能会给患者特别是青少年患者带来较大辐射伤害。因此,口腔临床上普遍采用曲面体层图像来判断下颌阻生智齿牙根与下颌管的位置关系;只有临床医生无法从曲面体层图像中做出确定性判读时,才会额外采集同一患者的CBCT图像进行辅助判断,以减少不必要的电离辐射伤害,即不是所有患者都会被要求采集CBCT图像数据[2]。临床上目前仍主要采取人工方式从曲面体层片中判断下颌阻生智齿牙根与下颌管的位置关系,准确性受医生经验、精力等人为因素影响较大。因此发展针对曲面体层片的下颌阻生智齿牙根与下颌管位置关系自动检测方法具有重要临床价值。
近年来,随着深度学习在图像目标检测、识别等任务中表现出良好性能,有部分学者将深度学习模型应用于口腔医学影像处理和分析领域。Ekert等[3]构建卷积神经网络模型用于判断曲面体层片中是否存在根尖病变;Chang等[4]将深度学习框架与传统计算机辅助诊断方法相结合,在牙周骨丢失和牙周炎分期的自动诊断任务中获得较高的准确性和良好的可靠性;Ariji等[5]使用多分类深度学习来检测釉细胞瘤、牙源性角化囊肿、含牙囊肿、根性囊肿和骨囊肿;Vinayahalingam等[6]使用一种基于U-net的深度学习方法对第3磨牙和下牙槽神经进行分割;Lee等[7]提出同时以曲面体层片和锥形束CT图像为数据集,通过迁移学习训练GoogLeNet Inception-v3模型,以提高牙源性囊性病变自动检测和诊断性能。
受上述研究启发,Fukuda等[8]使用预训练的AlexNet、GoogLeNet、VGG-16网络对曲面体层片中下颌阻生智齿牙根与下颌管的位置关系进行分类,获得了较好的分类结果;Choi等[9]也尝试采用经典的ResNet-50深度模型作为分类网络,以判断感兴趣区域内是否存在下颌阻生智齿牙根与下颌管相接触的情况。但已有的这些方法需要观察者在分类之前从整幅待检测图像中人工搜索包含下颌阻生智齿牙根与下颌管的区域,并将该感兴趣区域裁剪成图像块作为分类网络模型的输入,由于关键步骤需要人工操作,所以该方法检测结果准确性仍会受到临床医生经验差异的巨大影响。此外,该方法的另一个缺点是只能给出下颌阻生智齿牙根与下颌管位置关系的分类结果,无法自动预测图像中与下颌管接触的智齿牙根所在区域。
为了克服上述缺点,本文提出基于卷积神经网络的曲面体层片下颌阻生智齿牙根与下颌管位置关系自动检测方法,该方法以YOLOv5网络为框架构建可同时完成分类和回归任务的单步深度卷积神经网络。在测试过程中不涉及感兴趣区域的人工搜索和裁剪;对曲面体层图像进行一次扫描后,即可同时输出该图像中下颌阻生智齿牙根与下颌管接触的概率,以及可能存在两者相接触情况的区域;此外,使用相应的三维CBCT图像作为分类金标准来训练网络模型。
需要特别说明的是,因为本文所能采集到的数据中分别属于接触和重叠关系的样本数量均较少,故本文将接触和重叠关系统一归为下颌阻生智齿牙根与下颌管相互接触类别加以判断,即本文中数据的样本类别只有接触和非接触两类。
1. 方法介绍
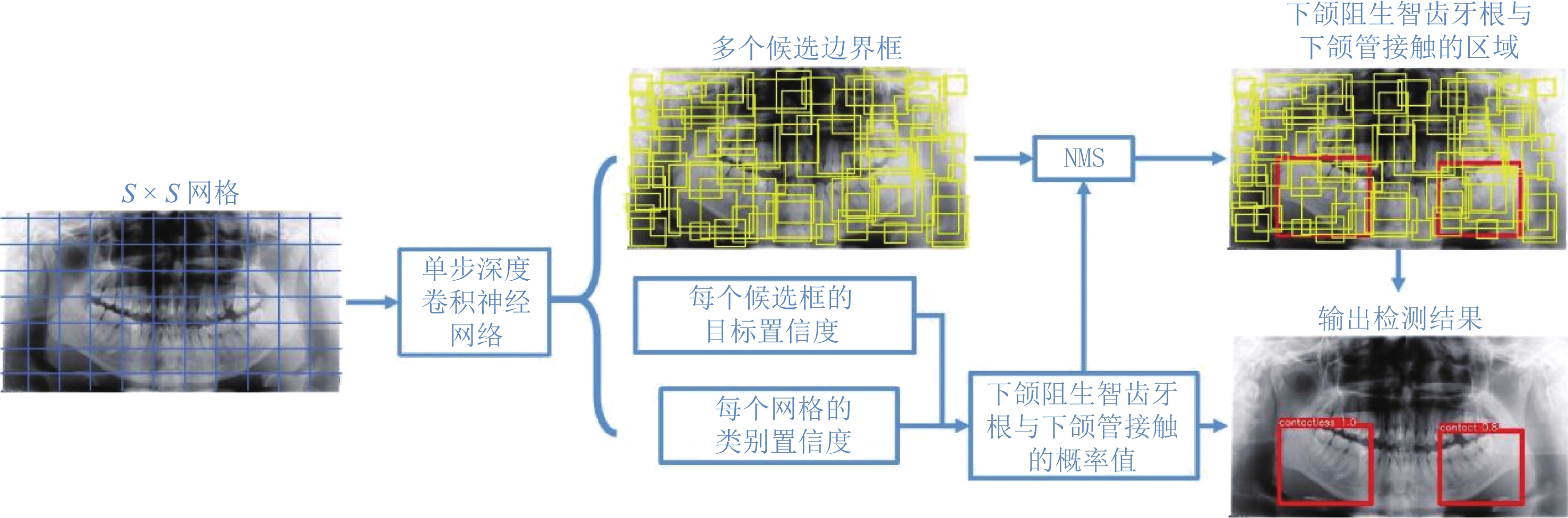
本文发展一种用于自动检测曲面体层图像中下颌阻生智齿牙根与下颌管位置关系的方法。图1为本文所提方法的自动检测流程图,以YOLOv5网络为框架构建单步深度卷积神经网络。采用Mosaic数据增强方式[10]扩充训练数据集,即将训练集中的曲面体层图像进行随机缩放、随机裁剪、随机排布后拼接在一起作为新的训练数据。接着将从二维曲面体层训练图像获得的定位标注信息和对应的CBCT训练图像获得的分类标注信息作为金标准,训练网络学习曲面体层片图像特征与智齿牙根与下颌管位置关系的非线性关系。
当采集到新的曲面体层图像后,将新图像划分成S×S个网格并随后输入到训练好的深度网络,会生成多个候选边界框及其对应的目标置信度,以及每个网格的类别置信度。这些候选边界框指出了可能存在下颌阻生智齿牙根与下颌管接触情况的区域,其对应的目标置信度表明边界框包含物体的概率;每个网格的类别置信度给出该网格中下颌阻生智齿牙根与下颌管接触的概率。通过非极大值抑制方法(non-maximum suppression,NMS),可以从所有候选边界框中筛选出包含相接触的下颌阻生智齿牙根与下颌管的最终区域框。将最终边界框的目标置信度乘以其所在网格的类别置信度即可获得该边界框包含的下颌阻生智齿牙根与下颌管相接触的概率值。如得到的概率值大于0.6,则认为下颌阻生智齿牙根与下颌管接触,从而完成分类任务。
1.1 网络结构
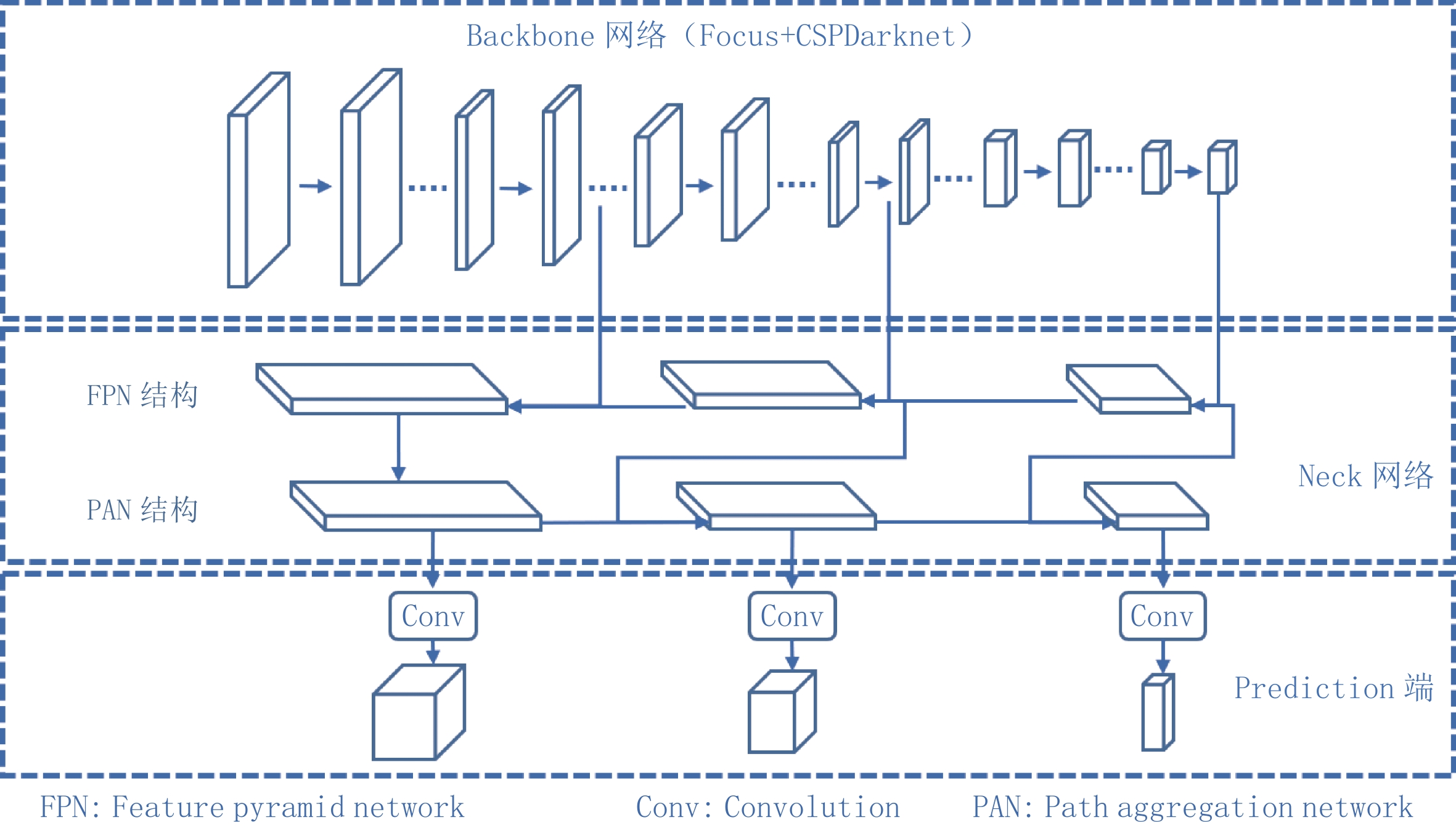
本文使用的单步深度学习网络主要分为Backbone网络、Neck网络和Prediction端3个部分,其结构图如图2所示。
Backbone网络采用Focus模块和CSPDarknet网络[11]的组合。Focus模块可以通过对输入图像进行切片操作后再卷积,在不丢失信息的情况实现下采样。跨阶段局部网络(cross stage partial,CSP)结构利用复制基础层的特征映射图,将基础层的特征映射图分离出来,在减少网络参数数量的同时能有效缓解梯度消失问题[10]。在Darknet中加入CSP模块构成CSPDarknet,可以在降低计算瓶颈的同时有效提高新网络的学习能力。相关参数在表1中列出。
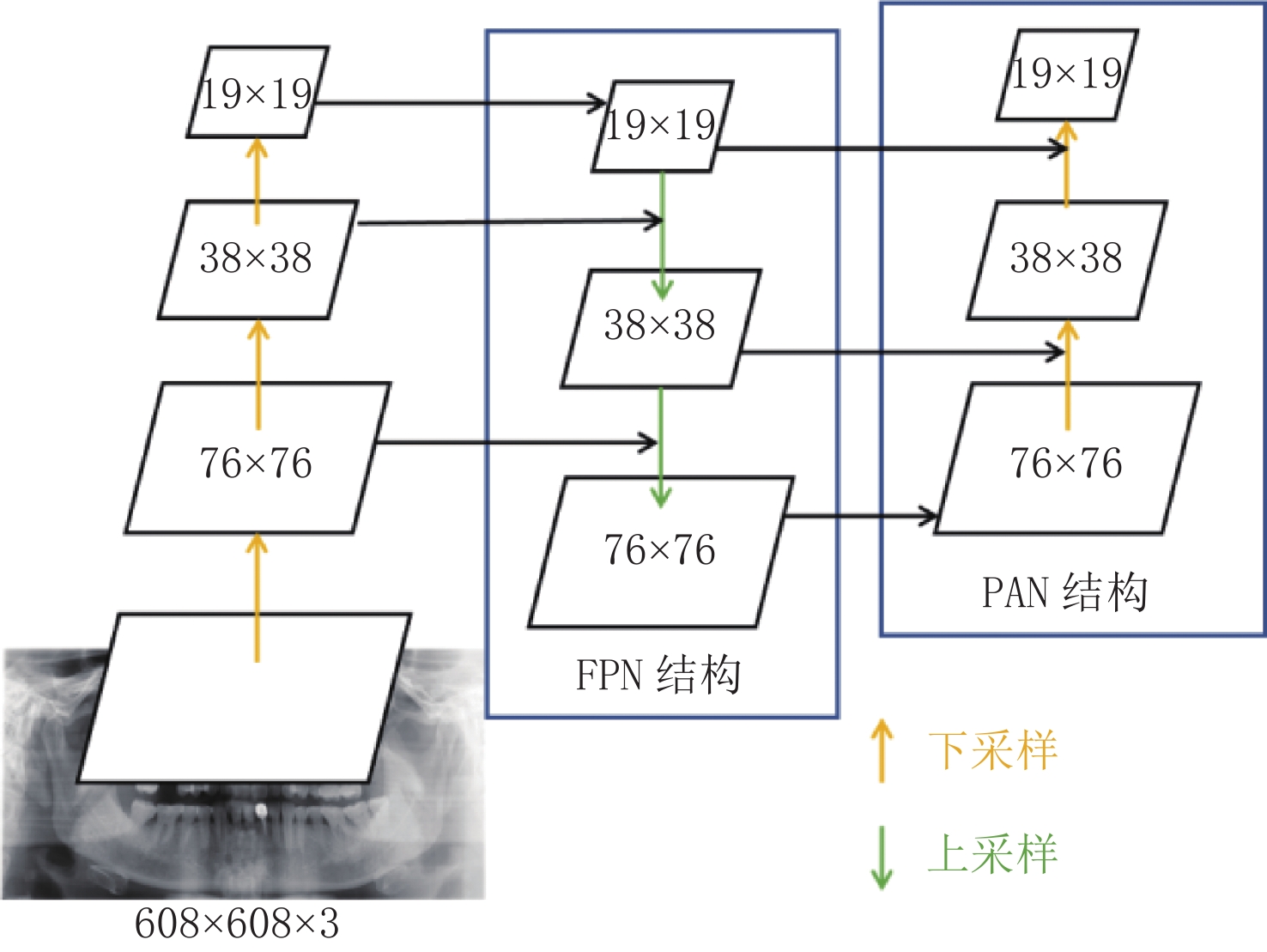
表 1 Backbone网络涉及的主要参数Table 1. The main parameters of the backbone network模块名称 数量 卷积核 尺寸 步长 输入尺寸 输出尺寸 Conv 1 80 3⊆3 2 608⊆608⊆3 304⊆304⊆80 Conv 1 160 3⊆3 2 304⊆304⊆80 152⊆152⊆160 CSP1_4 4 160 - - 152⊆152⊆160 152⊆152⊆160 Conv 1 320 3⊆3 2 152⊆152⊆160 76⊆76⊆320 CSP1_8 8 320 - - 76⊆76⊆320 76⊆76⊆320 Conv 1 640 3⊆3 2 76⊆76⊆320 38⊆38⊆640 CSP1_12 12 640 - - 38⊆38⊆640 38⊆38⊆640 Conv 1 1280 3⊆3 2 38⊆38⊆640 19⊆19⊆1280 CSP1_4 4 1280 - - 19⊆19⊆1280 19⊆19⊆1280 SPPF 1 1280 - - 19⊆19⊆1280 19⊆19⊆1280 Neck部分采用了FPN(feature pyramid networks)[12]和PAN(pyramid attention network)[13]的组合结构,如图3所示。其中FPN是自顶向下的结构,将从Backbone网络提取的高层曲面体层图像特征通过上采样,和底层曲面体层图像特征融合得到特征图。虽然能有效增强语义信息,但是对牙根与下颌管的定位信息没有传递。
针对该缺点,本文网络在FPN结构后面添加一个自底向上的PAN结构,将底层牙根与下颌管的定位信息有效传递到更高层的特征图,达到增强多个尺度上定位能力的目的。利用这种多尺度传递信息的策略,能够增强对不同尺度图像的鲁棒性。
值得注意的是,Backbone网络与Neck网络部分之间有3条捷径相连接,从而Neck部分可以充分利用从Backbone中提取的不同尺度的特征。而在Prediction端,当3种不同尺度特征从Neck网络传入后,经过卷积操作即可预测出多个候选边界框位置、尺寸大小及其对应的目标置信度,以及每个网格的类别类置信度。
本方法采用多尺度的输出端,针对大、中、小3种不同尺度的目标生成不同尺度的特征图预测。下采样倍数小的特征感受野小,适合处理小目标;下采样倍数高具有大的感受野,适合检测大目标。
1.2 损失函数
在训练阶段,本文网络所用的损失函数包括目标置信度损失、分类预测损失和边界框定位损失3部分。其中,目标置信度损失和分类预测损失由常见的二值交叉熵损失函数计算获得;由于传统的IOU(intersection over union)损失函数存在不能反映边界框真实位置与预测位置两者之间的距离大小及对齐方式等缺点,本文采用GIOU(generalized intersection over union)损失函数来计算边界框定位损失,其定义[14]如下:
$$\begin{aligned} {L}_{\mathrm{G}\mathrm{I}\mathrm{O}\mathrm{U}}=1-\mathrm{G}\mathrm{I}\mathrm{O}\mathrm{U}\qquad \\ \mathrm{G}\mathrm{I}\mathrm{O}{\rm{U}}=\mathrm{ }\mathrm{I}\mathrm{O}\mathrm{U}-|A-B|\mathrm{ }/\mathrm{ }\left|A\right| \end{aligned}\; ,$$ (1) 其中,IOU值可通过边界框位置真实值与预测值的交集面积除以并集面积获得;A表示两个边界框最小外接矩形的面积,B表示两个边界框并集的面积;LGIOU损失函数,取值范围为[0,2]。
2. 实验结果和讨论
本文实验所使用的数据集来自江苏省口腔医院。此数据集由1570幅曲面体层片图像及对应CBCT图像组成,其中共有798例样本存在下颌阻生智齿牙根与下颌管相接触情况,1745例样本无下颌阻生智齿牙根与下颌管相接触情况;曲面体层片图像分辨率为2976×1536像素。用于训练的图像数量为1256幅,用于验证的图像数量为157幅,剩余157幅图像被用于测试。
本文实验所用工作站采用了Intel Xeon E5-2678 v3 2.50 GHz的双核CPU,内存为32 GB,并配置GeForce GTX 1080 Ti GPU显卡1块。以下实验中训练迭代次数设为1200,batch_size设为6;采用Adam优化器,其参数为0.843;使用的激活函数为LeakyRelu;初始设定锚框的长宽为[151,126],[169,122],[153,140],[168,135],[180,130],[176,144],[166,157],[194,139],[191,155];为了适应网络模型对输入图像尺寸要求,将原图像缩放并以在图像边缘填充固定值的方式将图像尺寸调整至608×608,这里的固定值采用了缺省值114;学习率设为0.0032;参数S的取值由网络模型输入数据尺寸、Backbone网络结构以及输出数据尺寸自动计算获得。
本文通过准确率(accuracy)、灵敏度(sensitivity)、特异度(specificity)和精确度(precision)等指标来评估算法分类性能。表2列出利用人工判读、AlexNet、GoogLeNet、VGG-16、ResNet-50和本文模型方法,针对测试数据集中的曲面体层图像进行预测所得结果对应的准确率、灵敏度、特异度和精确度值。本文的人工判读结果由两组专业口腔颌面临床医生对测试图像数据进行独立评估获得;为了符合临床实际情况,设定测试时临床医生只能通过用于测试的曲面体层图像来判断下颌阻生智齿牙根与下颌管是否接触,没有对应的三维CBCT图像进行辅助判断。
表 2 本文方法与其他方法及人工判读所得预测结果对应的分类性能评价指标的对比Table 2. The comparison of classification performance for the proposed method, manual diagnosis, and the other models方法 准确率 灵敏度 特异度 精确度 人工判读 0.845 0.741 0.892 0.759 AlexNet 0.778 0.506 0.919 0.764 GoogLeNet 0.770 0.434 0.944 0.800 VGG-16 0.737 0.422 0.900 0.686 ResNet-50 0.831 0.663 0.919 0.809 本文方法 0.881 0.819 0.913 0.829 从表2可以看出,相对于AlexNet、GoogLeNet和VGG-16模型,由于本文所用网络模型在Backbone部分采用了性能优秀的CSPDarknet主干网络,并在Neck部分采用了FPN和PAN结构进行高效的特征信息传递,故在准确率、灵敏度、特异度和精确度方面具有明显的优势。值得注意的是,本文方法预测结果计算所得的TP(true positive)值(等于68)远高于AlexNet(等于42)、GoogLeNet(等于36)和VGG-16(等于35),阳性样本识别正确率接近82%,而AlexNet、GoogLeNet和VGG-16模型的阳性样本识别正确率仅为50%、43% 和42%,远低于本文方法。另外,AlexNet、GoogLeNet、VGG-16和本文方法所得FN(false negative)值分别为41、47、48和15,可见本文方法将阳性样本误判为阴性的数量远低于这3种模型。由于灵敏度评价指标主要与TP和FN值直接相关,故本文方法预测结果对应的灵敏度值远高于其他3种模型。
另外,本方法所得结果的准确率等评价指标值也略高于专业临床医生的人工判读结果。例如,在没有对应的CBCT图像进行辅助判断的情况下,临床医生人工判读所得TP值(等于62)低于本文方法(等于68),而其TN(true negative)值(等于143)亦低于本文方法(等于146),使得本文方法所得预测结果的准确率稍高于专业临床医生人工判读结果。本文方法所得预测结果略优于临床医生人工判读的可能原因为:曲面体层图像存在解剖结构相互重叠、缺乏颊舌向信息等固有缺点。因此,即使经验丰富的临床医生在没有对应的CBCT图像进行辅助判断的情况下,仅通过曲面体层图像进行判断会受到解剖结构相互重叠、缺乏颊舌向信息等固有缺点的影响,可能造成个别误判。
本节还探究了所提方法涉及的概率阈值、训练迭代次数、批大小、优化器参数以及学习率等参数对分类性能评价指标值的影响。表3列出了部分概率阈值对应的分类性能评价指标值。
表 3 部分概率阈值对应的分类性能评价指标值Table 3. The measurements of classification performance for different thresholds概率阈值 准确率 灵敏度 特异度 精确度 0.60 0.881 0.819 0.913 0.829 0.65 0.881 0.795 0.925 0.846 0.70 0.868 0.747 0.931 0.849 0.75 0.860 0.699 0.944 0.866 从表3可以看出:当概率阈值从0.60增加到0.75时,准确度指标值下降2.4%,灵敏度和精确度两项指标值分别上升3.4% 和4.5%;而灵敏度指标值下降了14.7%,其下降幅度远远超过特异度和精确度两项指标值的上升幅度。所以综合考虑,本文将概率阈值设定为0.6。
使用本文方法时,不同训练迭代次数、批大小、学习率以及优化器参数对应的各分类性能指标值请见表4。由表4可以发现:训练迭代次数取值为1200对应的性能指标全部高于取值为800时;而其灵敏度和精确度指标值稍低于1600次迭代训练,但是其灵敏度性能指标值远高于后者。故综合4个性能指标而言,训练迭代次数取值为1200时能获得最佳预测分类结果。至于批大小、学习率和优化器参数也存在类似情况。只有批大小等于6、学习率等于0.0032、优化器参数β1=0.843且β2=0.999时,对应的全部性能指标均超过0.800;而批大小、学习率和优化器参数其他取值对应的灵敏度性能指标有时甚至低于0.600。综合考虑,认为批大小等于6、学习率等于0.0032、优化器参数β1=0.843且β2=0.999时取得的预测分类结果最佳。
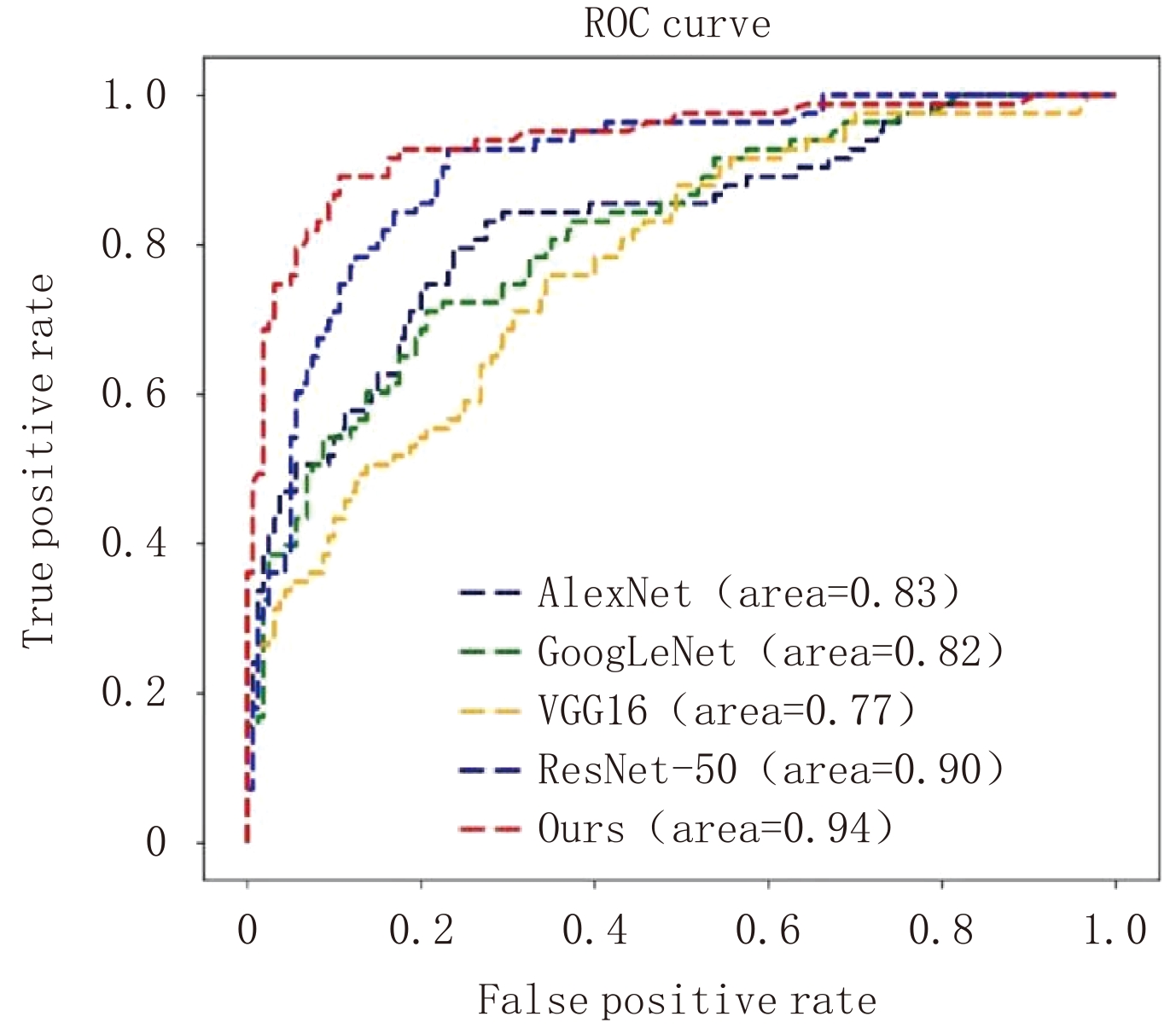
表 4 使用本文方法时,不同训练迭代次数、批大小、学习率以及优化器参数对应的各分类性能指标值Table 4. The measurements of classification performance for different iterations, epochs, learning rates, and parameters of the optimizer in the proposed method参数名称 参数取值 准确率 灵敏度 特异度 精确度 训练迭代次数 800 0.877 0.807 0.913 0.827 1200 0.881 0.819 0.913 0.829 1600 0.835 0.614 0.95 0.864 批大小 4 0.840 0.602 0.963 0.893 6 0.881 0.819 0.913 0.829 学习率 0.0022 0.889 0.759 0.956 0.900 0.0032 0.881 0.819 0.913 0.829 0.0042 0.823 0.590 0.944 0.845 优化器参数β1(β2=0.999) 0.743 0.868 0.723 0.944 0.870 0.843 0.881 0.819 0.913 0.829 0.943 0.864 0.747 0.925 0.838 优化器参数β2(β1=0.843) 0.9 0.856 0.675 0.950 0.875 0.99 0.868 0.759 0.925 0.840 0.999 0.881 0.819 0.913 0.829 为了进一步验证本文方法有效性,下面引入目标检测领域常用的ROC(receiver operating characteristic curve)曲线[15]和PR(precision-recall)曲线[16]以及AUC(area under curve)面积值[14]进行评估。图4比较了AlexNet、GoogLeNet、VGG-16、ResNet-50和本文方法所用模型预测结果的ROC曲线,其中右下角还显示了AUC面积值。
![]() 图 4 使用不同模型获得结果对应ROC曲线的对比Figure 4. The comparison of corresponding ROC curves of the results obtained using the different models
图 4 使用不同模型获得结果对应ROC曲线的对比Figure 4. The comparison of corresponding ROC curves of the results obtained using the different models结果表明,本方法所用网络在所有模型中达到了最高的AUC(0.94);与AlexNet、GoogLeNet、VGG-16和ResNet-50相比,本文网络的AUC分别提高了13.3%、14.6%、22.1% 和4.4%。另外,本文所用网络模型预测出的边界框位置对应的mAP(mean average precision)值等于0.835,表明本文方法能较准确地估计出存在相互接触的下颌阻生智齿牙根与下颌管所在区域位置。
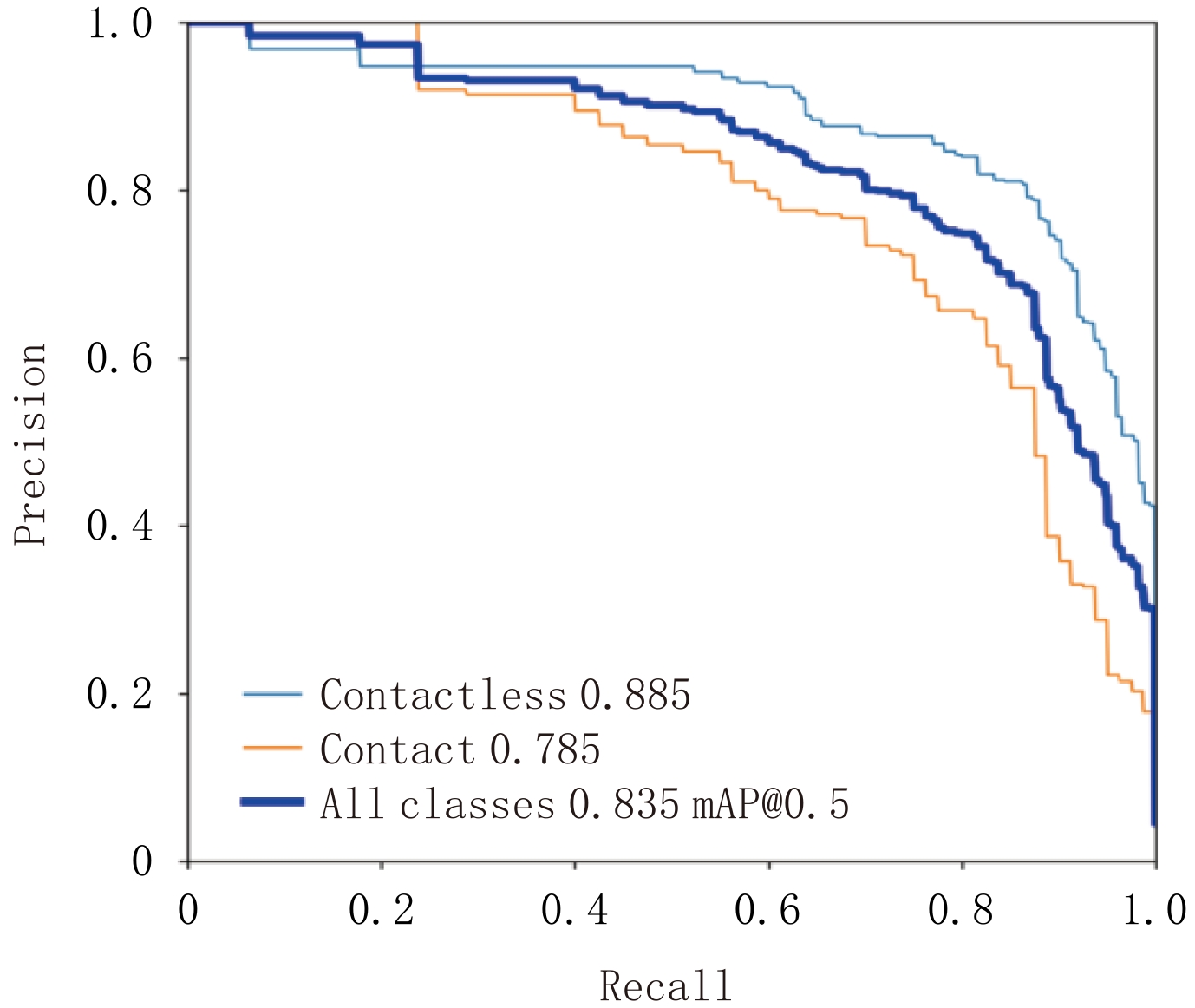
图5显示了在IOU设为0.5的情况下使用本文方法所得结果对应的PR曲线,其中淡蓝色曲线代表的是下颌阻生智齿牙根与下颌管无接触的PR曲线,其AP(average precision)值为0.885;黄色曲线代表的是下颌阻生智齿牙根与下颌管接触的PR曲线,其AP值为0.785;蓝色曲线代表这两类平均的PR曲线,其mAP值为0.835。可以看出,本文方法在以上两种类别均表现优异,其中在下颌阻生智齿牙根与下颌管无接触类别上表现更优。
![]() 图 5 使用本文方法所得结果对应的PR曲线Figure 5. The PR curves corresponding to the results obtained using the method in this paper
图 5 使用本文方法所得结果对应的PR曲线Figure 5. The PR curves corresponding to the results obtained using the method in this paper表5所列为本文所用深度网络与其他用于比较的网络模型参数数量对比,以此进行比较各种网络的计算复杂度。由表5可以看出,本文方法所用网络模型涉及参数量低于VGG-16模型且高于其他模型。
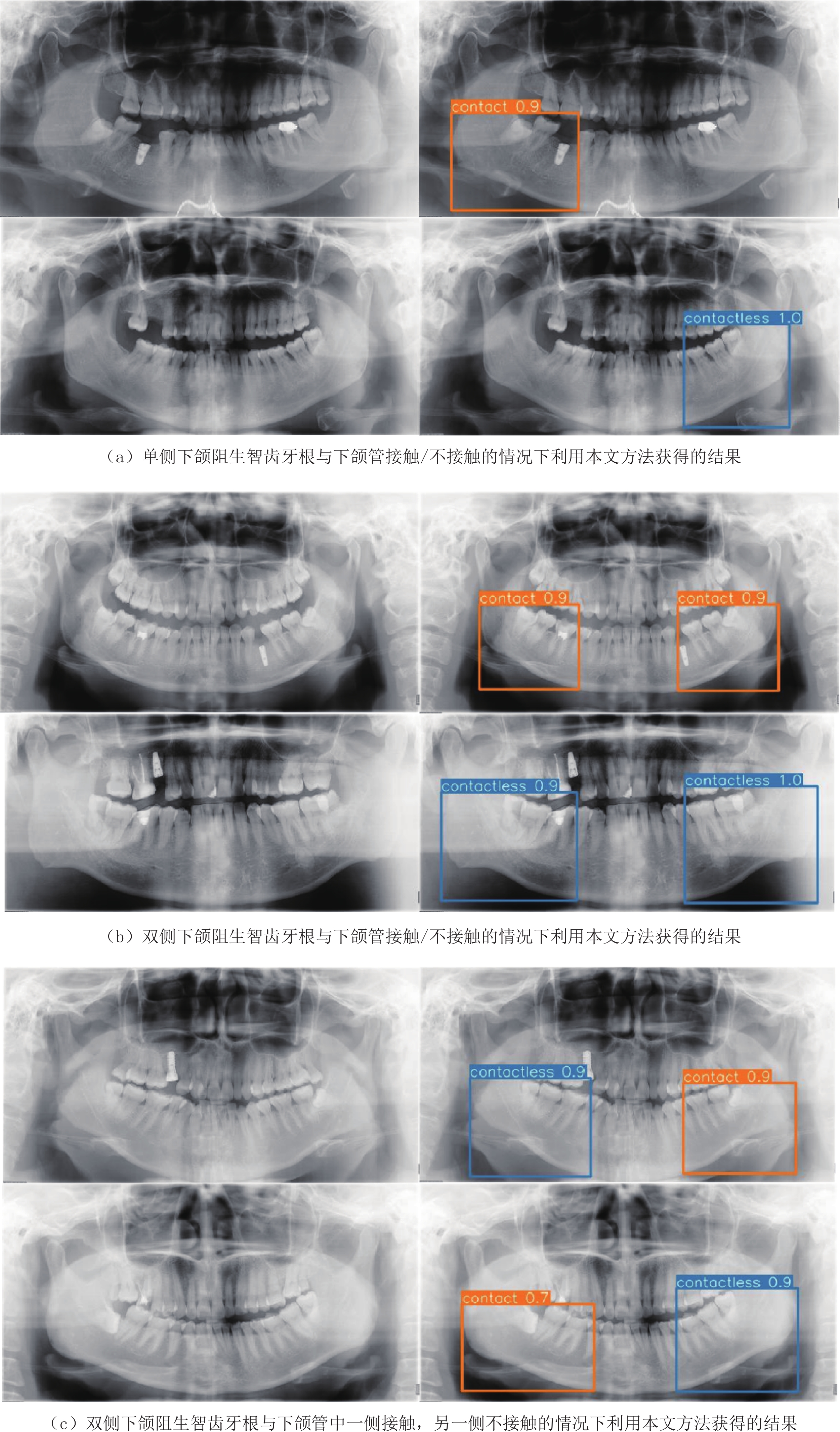
表 5 本文所用深度网络与其他模型涉及参数数量的对比Table 5. The comparison of the number of parameters used in our network and the others网络模型 AlexNet GoogLeNet VGG-16 ResNet-50 本文方法 参数量/M 61.0 7.0 138.4 25.5 87.3 图6展示了本文方法的输出结果,其中,图6(a)为单侧下颌阻生智齿牙根与下颌管接触/不接触的情况下利用本文方法获得的结果,图6(b)为双侧下颌阻生智齿牙根与下颌管接触/不接触的情况下利用本文方法获得的结果,图6(c)为双侧下颌阻生智齿牙根与下颌管中一侧接触,另一侧不接触的情况下利用本文方法获得的结果。
![]() 图 6 使用本文方法得到的输出结果每一行左侧图像均为原始图像,右侧是本文方法输出结果图。结果图中的棕色字符contact代表下颌阻生智齿牙根与下颌管的位置关系是接触状态,蓝色字符contactless代表两者没有接触;棕色数字是预测为接触的置信度,蓝色数字是预测为不接触的置信度。Figure 6. Demonstration of the output results obtained from the proposed method in this paper
图 6 使用本文方法得到的输出结果每一行左侧图像均为原始图像,右侧是本文方法输出结果图。结果图中的棕色字符contact代表下颌阻生智齿牙根与下颌管的位置关系是接触状态,蓝色字符contactless代表两者没有接触;棕色数字是预测为接触的置信度,蓝色数字是预测为不接触的置信度。Figure 6. Demonstration of the output results obtained from the proposed method in this paper每一行左侧都是原始输入图像,右侧是本文方法输出的结果图。结果图中的棕色字符contact代表下颌阻生智齿牙根与下颌管的位置关系是接触状态,蓝色字符contactless代表两者没有接触;棕色数字是预测为接触的置信度,蓝色数字是预测为不接触的置信度。可以看到,本文方法准确地判断出下颌阻生智齿牙根与下颌管的位置关系,同时能准确估计出存在下颌阻生智齿牙根与下颌管相接触情况的区域。
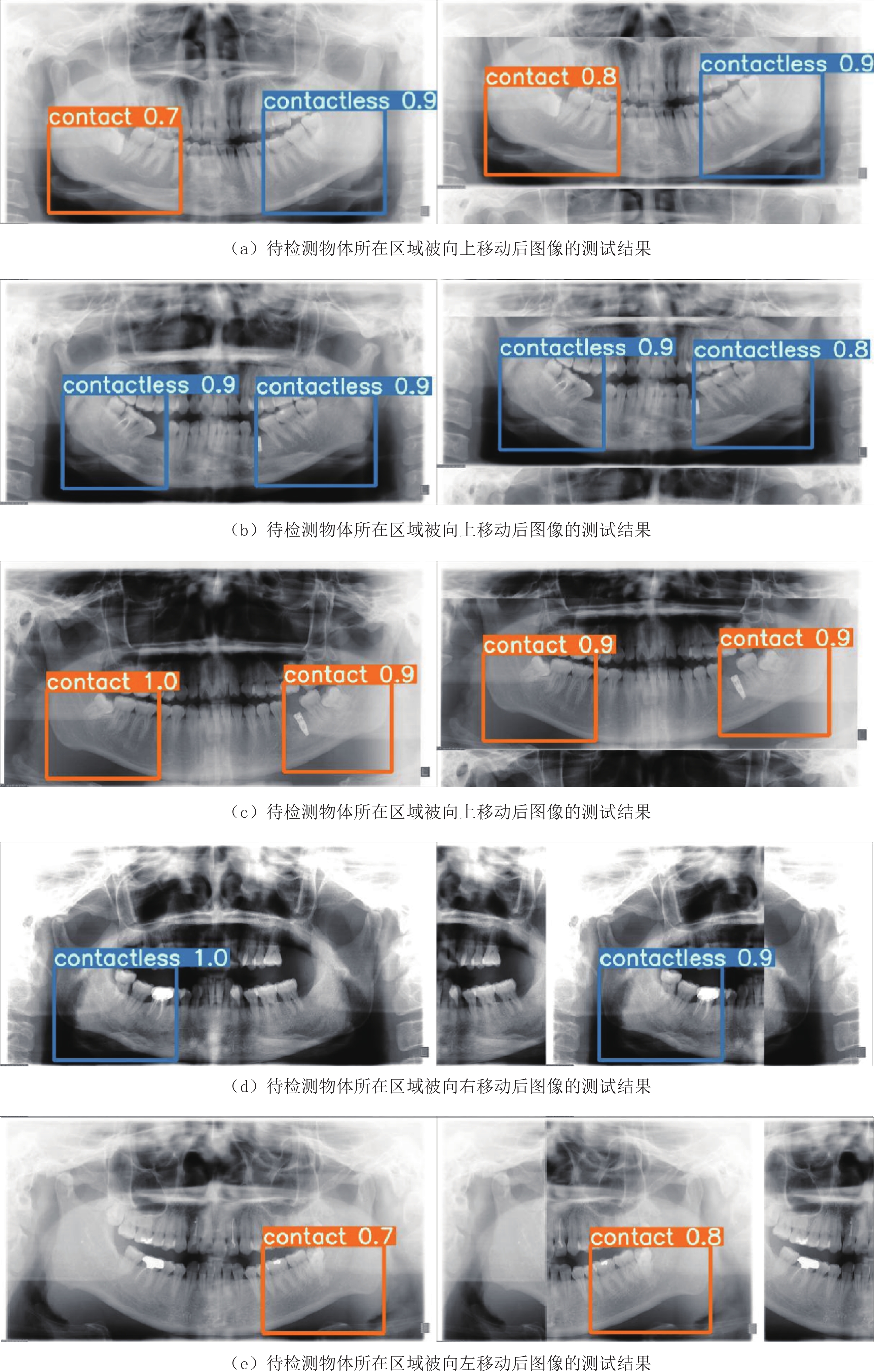
为了进一步测试本文方法的有效性,将测试图像中待检测物体所在区域朝不同方向移动并裁剪后,利用本文已训练模型对补全的图像进行检测,其中,共有32张图像中的待检测物体向右移动,39张图像中的待检测物体向左移动,86张图像中的待检测物体向上移动。
图7显示了待检测物体所在区域被不同方向移动后图像的部分测试结果。从图7可以看出,虽然待检测物体所在区域朝不同方向发生了移动,但是本文模型仍然能在移动并补全后的图像中准确检测出其所在区域,且模型输出的下颌阻生智齿牙根与下颌管接触的概率值与移动前基本一致。
![]() 图 7 待检测物体所在区域被不同方向移动后图像的部分测试结果Figure 7. Some examples of predicted results, after the regions including the objects to be detected in panoramic images, have been shifted in different directions
图 7 待检测物体所在区域被不同方向移动后图像的部分测试结果Figure 7. Some examples of predicted results, after the regions including the objects to be detected in panoramic images, have been shifted in different directions表6列出了所有测试图像中待检测物体所在区域朝不同方向移动前和移动后,本文方法分别获得的预测结果分类性能评价指标平均值。从表6可以看出,待检测物体所在区域朝不同方向移动前后,本文方法的分类性能总体未发生显著变化。图7和表6可以证实:即使待检测物体所在区域在不同方向发生移动,本文模型仍然能保持较好的性能。
表 6 待检测物体所在区域朝不同方向移动前和移动后,本文方法对测试图像所得预测结果的分类性能评价指标对比Table 6. The comparison of classification performance for the predicted results between the cases with or without the regions including the targets shifted in different directions方法 准确度 灵敏度 特异度 精确度 移动前 0.881 0.819 0.913 0.829 移动后 0.864 0.723 0.938 0.857 3. 结论
为了提高曲面体层图像中下颌阻生智齿牙根与下颌管位置关系的识别精度和效率,本文提出一种基于单步深度卷积神经网络的自动检测方法。该方法对曲面体层图像进行检测时无需任何人工操作,能有效克服临床医生经验差异等主观因素对检测精度的影响。实验结果证明,本文方法能够较准确地判断下颌阻生智齿牙根与下颌管的位置关系,并同时预测出可能存在下颌阻生智齿牙根与下颌管相接触情况的区域。
本文方法存在检测框过大的问题,在未来工作中,本文作者将对所有1570幅图像数据重新标注检测框,缩小检测框尺寸使之更加聚焦阻生智齿牙根与下颌管接触位置。
-
![]()
图 4 使用不同模型获得结果对应ROC曲线的对比
Figure 4. The comparison of corresponding ROC curves of the results obtained using the different models
![]()
图 5 使用本文方法所得结果对应的PR曲线
Figure 5. The PR curves corresponding to the results obtained using the method in this paper
![]()
图 6 使用本文方法得到的输出结果
每一行左侧图像均为原始图像,右侧是本文方法输出结果图。结果图中的棕色字符contact代表下颌阻生智齿牙根与下颌管的位置关系是接触状态,蓝色字符contactless代表两者没有接触;棕色数字是预测为接触的置信度,蓝色数字是预测为不接触的置信度。
Figure 6. Demonstration of the output results obtained from the proposed method in this paper
![]()
图 7 待检测物体所在区域被不同方向移动后图像的部分测试结果
Figure 7. Some examples of predicted results, after the regions including the objects to be detected in panoramic images, have been shifted in different directions
表 1 Backbone网络涉及的主要参数
Table 1 The main parameters of the backbone network
模块名称 数量 卷积核 尺寸 步长 输入尺寸 输出尺寸 Conv 1 80 3⊆3 2 608⊆608⊆3 304⊆304⊆80 Conv 1 160 3⊆3 2 304⊆304⊆80 152⊆152⊆160 CSP1_4 4 160 - - 152⊆152⊆160 152⊆152⊆160 Conv 1 320 3⊆3 2 152⊆152⊆160 76⊆76⊆320 CSP1_8 8 320 - - 76⊆76⊆320 76⊆76⊆320 Conv 1 640 3⊆3 2 76⊆76⊆320 38⊆38⊆640 CSP1_12 12 640 - - 38⊆38⊆640 38⊆38⊆640 Conv 1 1280 3⊆3 2 38⊆38⊆640 19⊆19⊆1280 CSP1_4 4 1280 - - 19⊆19⊆1280 19⊆19⊆1280 SPPF 1 1280 - - 19⊆19⊆1280 19⊆19⊆1280  下载: 导出CSV
下载: 导出CSV
表 2 本文方法与其他方法及人工判读所得预测结果对应的分类性能评价指标的对比
Table 2 The comparison of classification performance for the proposed method, manual diagnosis, and the other models
方法 准确率 灵敏度 特异度 精确度 人工判读 0.845 0.741 0.892 0.759 AlexNet 0.778 0.506 0.919 0.764 GoogLeNet 0.770 0.434 0.944 0.800 VGG-16 0.737 0.422 0.900 0.686 ResNet-50 0.831 0.663 0.919 0.809 本文方法 0.881 0.819 0.913 0.829
下载: 导出CSV
表 3 部分概率阈值对应的分类性能评价指标值
Table 3 The measurements of classification performance for different thresholds
概率阈值 准确率 灵敏度 特异度 精确度 0.60 0.881 0.819 0.913 0.829 0.65 0.881 0.795 0.925 0.846 0.70 0.868 0.747 0.931 0.849 0.75 0.860 0.699 0.944 0.866
下载: 导出CSV
表 4 使用本文方法时,不同训练迭代次数、批大小、学习率以及优化器参数对应的各分类性能指标值
Table 4 The measurements of classification performance for different iterations, epochs, learning rates, and parameters of the optimizer in the proposed method
参数名称 参数取值 准确率 灵敏度 特异度 精确度 训练迭代次数 800 0.877 0.807 0.913 0.827 1200 0.881 0.819 0.913 0.829 1600 0.835 0.614 0.95 0.864 批大小 4 0.840 0.602 0.963 0.893 6 0.881 0.819 0.913 0.829 学习率 0.0022 0.889 0.759 0.956 0.900 0.0032 0.881 0.819 0.913 0.829 0.0042 0.823 0.590 0.944 0.845 优化器参数β1(β2=0.999) 0.743 0.868 0.723 0.944 0.870 0.843 0.881 0.819 0.913 0.829 0.943 0.864 0.747 0.925 0.838 优化器参数β2(β1=0.843) 0.9 0.856 0.675 0.950 0.875 0.99 0.868 0.759 0.925 0.840 0.999 0.881 0.819 0.913 0.829
下载: 导出CSV
表 5 本文所用深度网络与其他模型涉及参数数量的对比
Table 5 The comparison of the number of parameters used in our network and the others
网络模型 AlexNet GoogLeNet VGG-16 ResNet-50 本文方法 参数量/M 61.0 7.0 138.4 25.5 87.3
下载: 导出CSV
表 6 待检测物体所在区域朝不同方向移动前和移动后,本文方法对测试图像所得预测结果的分类性能评价指标对比
Table 6 The comparison of classification performance for the predicted results between the cases with or without the regions including the targets shifted in different directions
方法 准确度 灵敏度 特异度 精确度 移动前 0.881 0.819 0.913 0.829 移动后 0.864 0.723 0.938 0.857
下载: 导出CSV
-
[1] 王东苗, 金致纯, 丁旭, 等. 锥形束CT评估下颌阻生智齿拔除术后下牙槽神经损伤的风险[J]. 南京医科大学学报(自然科学版), 2016,36(10): 1263−1266. [2] WANG D M, HE X T, WANG Y L, et al. Topographic relationship between root apex of mesially and horizontally impacted mandibular third molar and lingual plate: Cross-sectional analysis using CBCT[J]. Scientific Reports, 2016, 6(1): 39268−39278. doi: 10.1038/srep39268
[3] EKERT T, KROIS J, MEINHOLD L, et al. Deep learning for the radiographic detection of apical lesions[J]. Journal of Endodontics, 2019, 45(7): 917−922. doi: 10.1016/j.joen.2019.03.016
[4] CHANG H J, LEE S J, YONG T H, et al. Deep learning hybrid method to automatically diagnose periodontal bone loss and stage periodontitis[J]. Scientific Reports, 2020, 10(1): 7531−7539. doi: 10.1038/s41598-020-64509-z
[5] ARIJI Y, YANASHITA Y, KUTSUNA S, et al. Automatic detection and classification of radiolucent lesions in the mandible on panoramic radiographs using a deep learning object detection technique[J]. Oral Surgery, Oral Medicine, Oral Pathology and Oral Radiology, 2019, 128(4): 424−430. doi: 10.1016/j.oooo.2019.05.014
[6] VINAYAHALINGAM S, TONG X, BERGÉ S, et al. Automated detection of third molars and mandibular nerve by deep learning[J]. Scientific Reports, 2019, 9(1): 9007−9014. doi: 10.1038/s41598-019-45487-3
[7] LEE J, KIM D, JEONG S. Diagnosis of cystic lesions using panoramic and cone beam computed tomographic images based on deep learning neural network[J]. Oral Diseases, 2020, 26(1): 152−158. doi: 10.1111/odi.13223
[8] FUKUDA M, ARIJI Y, KISE Y, et al. Comparison of 3 deep learning neural networks for classifying the relationship between the mandibular third molar and the mandibular canal on panoramic radiographs[J]. Oral Surgery, Oral Medicine, Oral Pathology and Oral Radiology, 2020, 130(3): 336−343. doi: 10.1016/j.oooo.2020.04.005
[9] CHOI E, LEE S, JEONG E, et al. Artificial intelligence in positioning between mandibular third molar and inferior alveolar nerve on panoramic radiography[J]. Scientific Reports, 2022, 12(1): 2456−2463. doi: 10.1038/s41598-022-06483-2
[10] ZWA B, LJA B, SHUAI W. Apple stem/calyx real-time recognition using YOLO-v5 algorithm for fruit automatic loading system[J]. Postharvest Biology and Technology, 2022, 185(2): 111808−111815.
[11] BOCHKOVSKIY A, WANG C Y, LIAO H. YOLOv4: Optimal speed and accuracy of object detection[J]. arXiv Preprint, 2020, arXiv: 2004.10934v1.
[12] LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017: 2117-2125.
[13] LI H, XIONG P, AN J, et al. Pyramid attention network for semantic segmentation[J]. arXiv Preprint, 2018, arXiv:1805.10180.
[14] REZATOFIGHI H, TSOI N, GWAK J Y. Generalized Intersection over Union: A metric and a loss for bounding box regression[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019: 658-666.
[15] COOK N R. Use and misuse of the receiver operating characteristic curve in risk prediction[J]. Circulation, 2007, 115(7): 928−35. doi: 10.1161/CIRCULATIONAHA.106.672402
[16] BUCKLAND M K, GEY F C. The relationship between recall and precision[J]. Journal of the Association for Information Science & Technology, 2010, 45(1): 12−19.
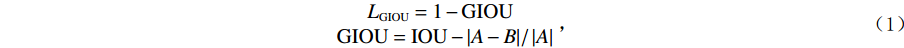
计量
- 文章访问数: 381
- HTML全文浏览量: 128
- PDF下载量: 43


