
Low-dose CT Image Reconstruction Method Based on CNN and Transformer Coupling Network
-
摘要: 在投影角度个数不变的情况下,降低每个角度下的射线剂量,是一种有效的低剂量CT实现方式,然而,这会使得重建图像的噪声较大。当前,以卷积神经网络(CNN)为代表的深度学习图像去噪方法已经成为低剂量CT图像去噪的经典方法。受Transformer在计算机视觉任务中展现的良好性能的启发,本文提出一种CNN和Transformer耦合的网络(CTC),以进一步提高CT图像去噪的性能。CTC网络综合运用CNN的局部信息关联能力和Transformer的全局信息捕捉能力,构建8个由CNN部件和一种改进的Transformer部件构成的核心网络块,并基于残差连接机制和信息复用机制将之互联。与现有4种去噪网络比较,CTC网络去噪能力更强,可以实现高精度低剂量CT图像重建。Abstract: Under the condition that the number of projection angles is constant, reducing the radiation dose under each angle is an effective way to realize low-dose CT. However, the reconstructed images obtained through this method can be very noisy. At present, the deep learning image denoising method represented by convolutional neural networks (CNN) has become a classical method for low-dose CT image denoising. Inspired by the good performance of transformer in computer vision tasks, this paper proposes a CNN transformer coupling network (CTC) to further improve the performance of CT image denoising. CTC network makes comprehensive use of local information association ability of CNN and global information capture ability of transformer, constructs eight core network blocks composed of CNN components and an improved transformer component, which are interconnected based on residual connection mechanism and information reuse mechanism. Compared with the existing four denoising networks, CTC network demonstrate better denoising ability and can realize high-precision low-dose CT image reconstruction.
-
计算机断层成像(computed tomography,CT)技术[1]是基于不同物质对X射线的衰减不同,使用X射线源和探测器阵列,对物体进行多个不同角度的扫描,再经过重建算法获得被检物体各个断层图像的影像技术[2]。但较大的X射线剂量会引起一定的辐射危害,人们通过降低辐射剂量获取低剂量CT图像[3],减小辐射危害风险。但随着X射线剂量的降低,重建出的CT图像噪声较大,严重劣化图像质量,影响后续的医学诊断[4]。近年来,为了解决这一问题,人们提出了许多算法来改善低剂量CT图像质量,其中,卷积神经网络(convolutional neural networks,CNN)[5]已被证明在解决图像去噪任务方面具有很好的潜力,并能取得比传统方法更好的性能[6]。
对于现有的CNN图像去噪网络,研究人员设计了多种不同的模型结构,包括全连接卷积神经网络、具有残差连接[7]的卷积编码解码网络、以及一些使用3D信息的网络变体[8]等,所以CNN已成为解决低剂量CT图像去噪问题的重要方法之一[9]。
卷积神经网络凭借其强大的非线性映射能力在图像去噪领域的应用越来越广泛。2016年Zhang等[10]提出了DNCNN网络,一种利用残差学习和批归一化进行端到端可训练的深度卷积来进行高斯去噪;2017年Chen等[11]提出了RED-CNN网络,将残差连接运用于编码器和解码器之间以弥补上采样造成的信息失真等问题;2018年Zhang等[12]提出了FFDNet网络,将高斯噪声泛化为更加复杂的真实噪声,并将噪声水平图作为网络输入的一部分,通过调整噪声水平进行更加灵活的去噪;2019年Anwar等[13]提出了RIDNet网络,使用特征注意力机制加强了网络的通道依赖性,并采用模块化结构实现了对真实图像的盲去噪能力;2020年Tian等[14]提出BRDNet网络,使用两个并行的网络模型,并通过扩张卷积提升感受也获取更多细节信息。
卷积神经网络对处理低剂量CT图像的复杂噪声具有很大的优势,能在保证去噪效果的同时更好地保留图像的细节和边缘信息[15],但同时也存在来自基本卷积层的两个问题。首先,图像和卷积内核之间的交互作用是与内容无关的,使用相同的卷积核来恢复不同的图像区域可能不是最好的选择;其次,在局部处理的原理下,卷积对于长期依赖建模是无效的[16]。
针对以上问题,最近Transformer以一种自注意机制的方式来捕获上下文之间的全局交互[17],并利用其对数据中远程依赖进行建模使其在计算机视觉领域大放光彩[18]。其中,2020年Google团队提出Vit Transformer,该网络模型首次将Transformer应用于图像分类任务,将整幅图像拆分成小图像块,然后把这些小图像块的线性序列作为Transformer的输入,使用监督学习的方式进行训练[19];2021年Liu等[20]提出了Swin Transformer网络架构,利用滑动窗口和分层结构,将注意力的计算限制在一个窗口中,在更好的利用细节信息的同时减少了计算量;2021年Wang等[21]提出了一种Uformer网络模型,设计了具有局部增强能力的Transformer模块,使用跳跃连接机制更有效的将编码器的信息传递到解码器。
受上述启发,本文提出一种CNN和Transformer耦合的网络(CNN-transformer- coupling network,CTC),利用多残差机制和信息复用机制,实现高精度低剂量CT图像重建。
1. 方法
低剂量CT图像去噪对临床医学诊断具有重要意义,深度学习法可以从大量的数据集中学习到难以被数学建模的图像特征和先验信息,具有很大的优势。近几年来,随着Vit Transformer的开创,Transformer在计算机视觉领域表现出巨大的应用潜力[22]。
受Swin Transformer的启发,本文将具有全局建模能力的Transformer和具有捕获局部特征的CNN有机的耦合,提出以CNN部件和一种改进的Transformer部件构成的核心网络块,即CNN和Transformer耦合模块(CNN-transformer-coupling block,CTCB)[23],且为更好的提取图像中的边缘轮廓信息,我们使用多方向的索贝尔算法作为图像边缘增强模块(image edge enhancement block,IEEB)的主要构成,实现有效去噪的同时保留了更完整的图像细节信息。
1.1 CNN和Transformer耦合模块(CTCB)
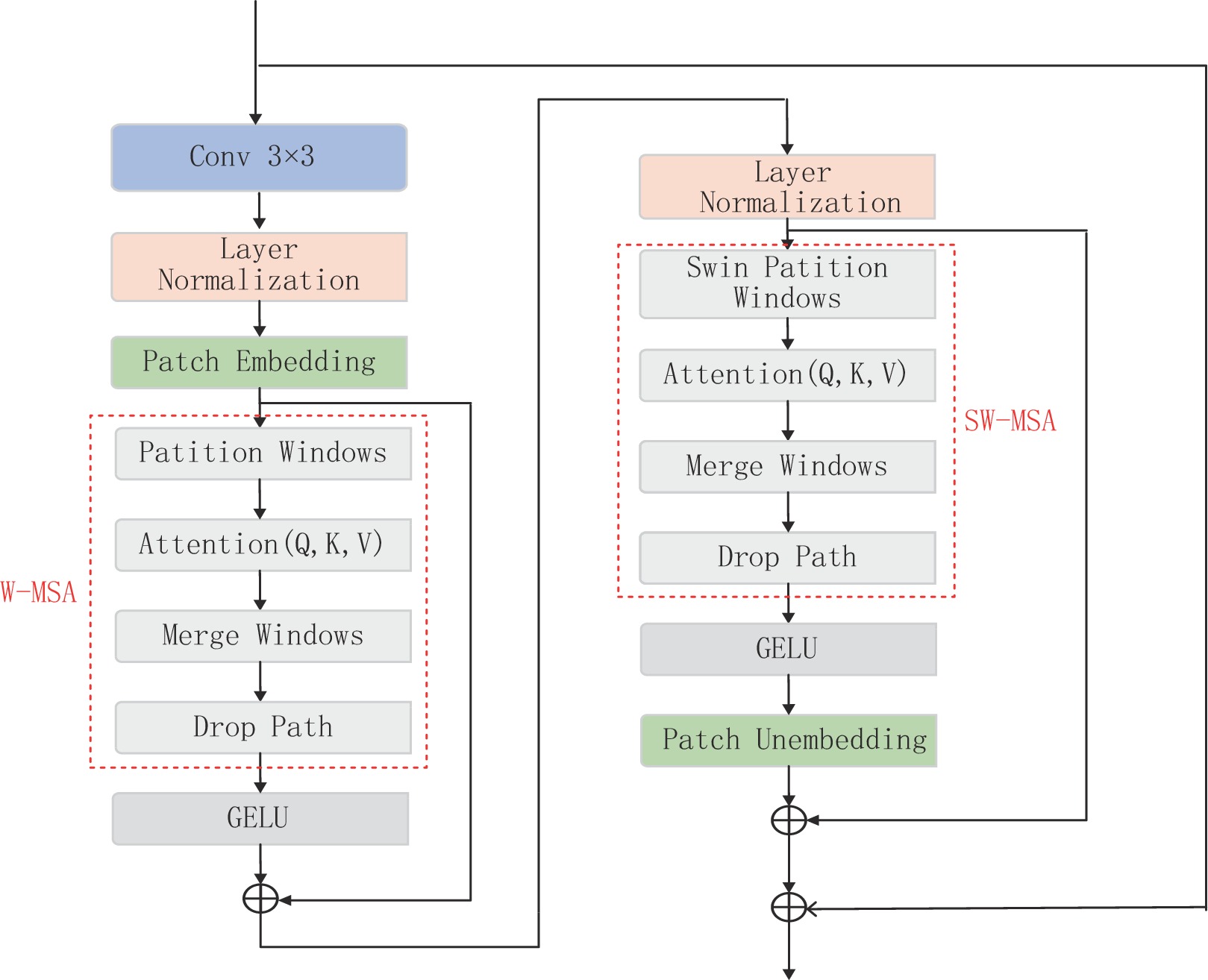
本文中提出的CNN和Transformer耦合模块(CTCB)由3部分组成,第1部分是3×3的卷积层(conv);第2部分是归一化层(layer normalization),多头自注意力(W-MSA)和GRLU激活函数;第3部分是归一化层(layer normalization),具有滑动窗口的多头自注意力(SW-MSA)和GELU激活函数,且采用了多残差机制。
CNN和Transformer耦合模块(图1),实现了CNN和Transformer优势的融合。这样设计的网络,一方面具有CNN的局部感知和参数共享特性,将原始图像作为输入,直接从大量样本中学习相应特征,避免使用复杂的特征提取过程捕获局部结构;另一方面又具有Transformer的动态注意全局特征和更好的泛化能力,且运用了滑动窗口机制,能在参数较少的情况下提取有效信息实现去噪。
具体过程是将
$ H\times W\times C $ 的矩阵作为输入,其中$ H\times W $ 为输入图像的大小,$ C $ 为输入通道数。通过卷积变换,将输入划分为不重叠的$ M\times M $ 局部窗口,窗口总数为$ HW/{M}^{2} $ ,则输入转化为$ (HW/{M}^{2})\times {M}^{2}\times C $ 对每个窗口分别进行注意力A计算,对于窗口特征$ \boldsymbol{X}\in {R}^{{M}^{2}\times C} $ 对应的Query,Key,Value矩阵计算为:$$ {\boldsymbol{Q}}={\boldsymbol{X}}{\boldsymbol{P}}_{Q},{\boldsymbol{K}}={\boldsymbol{X}}{\boldsymbol{P}}_{K},{\boldsymbol{V}}={\boldsymbol{X}}{\boldsymbol{P}}_{V}, $$ (1) 其中
$ {\boldsymbol{P}}_{Q} $ ,$ {\boldsymbol{P}}_{K} $ ,$ {\boldsymbol{P}}_{V}, $ 是跨不同窗口共享的投影矩阵,且$ \boldsymbol{Q} $ ,$ \boldsymbol{K} $ ,$ \boldsymbol{V}\in {R}^{{M}^{2}\times d} $ ,其中d为Q/K的维度,则注意力矩阵在对应窗口中自注意力机制计算为:$$ {\boldsymbol{A}}({\boldsymbol{Q}},{\boldsymbol{K}},{\boldsymbol{V}}) = {\rm{soft}}\;\max \left( {\frac{{\boldsymbol{ Q}}{{\boldsymbol{K}}^{\rm{T}}}}{{\sqrt {{d}} }} + {\boldsymbol{B}}} \right){\boldsymbol{V}} \text{,} $$ (2) 其中B是可学习的相对位置编码。本文实现两次自注意力计算,并将结果串联起来构成多头自注意力(W-MSA),之后连接GELU非线性激活层完成第2部分。第3部分通过移动窗口,再次进行多头自主注意力机制(SW-MSA),并连接GELU非线性激活层。
1.2 图像边缘增强模块(IEEB)
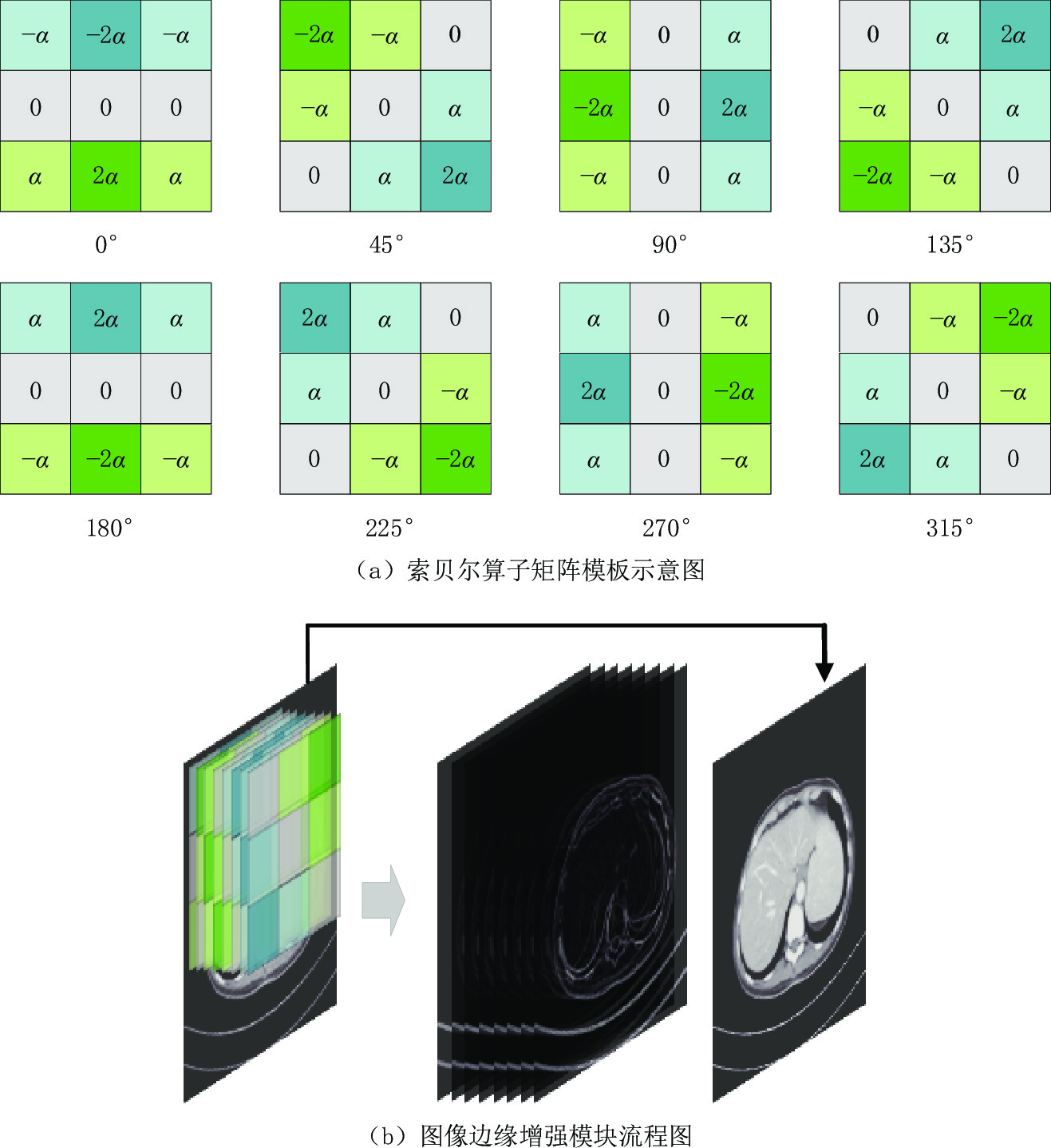
常用于边缘检测的索贝尔算子使用简单、处理速度快且对噪声具有平滑抑制作用,所得图像边缘光滑且连续[24]。为更好的提取图像信息,本文中的图像边缘增强模块利用0°、45°、90°、135°、180°、225°、270°、315° 这8个方向的索贝尔算子矩阵模板(3×3)与对应的图像进行卷积,每个模板对相应方向的边缘影响最大,如图2(a)所示。且该模块中加入可学习参数α,可以在训练过程中进行自适应调整,提取不同强度的细节信息,以更好的适用于肺部、腹部和头部的边缘提取。
具体流程图如图2(b)所示,索贝尔算子的中心与要检测的像素点相对应,进行卷积运算后,得到一组用于提取边缘信息的特征图。该模块将其与输入的低剂量CT图像在通道维度上叠加在一起,得到一幅边缘增强图像。
1.3 网络结构整体设计
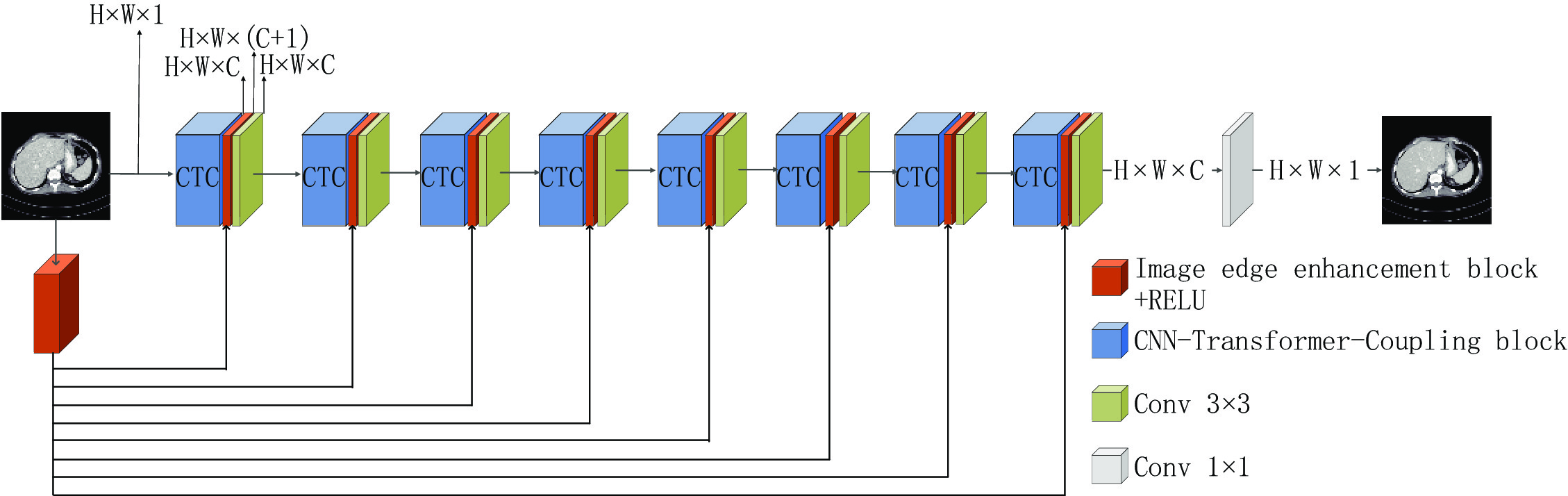
本文提出的CTC网络结构如图3所示,用于低剂量CT图像去噪。整个网络模型共有9层,其中前8层结构一致,每一层由CNN和Transformer耦合模块(CTCB)、图像边缘增强模块(IEEB)和3×3卷积层组成。输入的图像经过图像边缘增强之后,得到的特征图像通过残差连接与CNN和Transformer耦合模块以叠加通道数的方式进行融合。之后运用3×3的卷积使通道数转换为32,以保证传播过程中通道数不发生变化,目的是尽可能地保留图像的细节信息,充分利用提取的边缘信息和原始输入。运用多残差机制有效避免了因网络过深而带来的梯度消失和梯度爆炸问题,更合理的利用图像信息。
采用图像边缘增强的信息复用机制,在每一个单元与核心模块融合再利用,使图像的轮廓更加突出,保留更加完整的细节信息。网络中通道数为32,自注意力头数为2。最后一层为1×1的卷积层,将通道数转换为输出通道数,并输出图像。
受Swin Transformer的启发,我们在多头自注意力计算后采用多层感知器(MLP)[25]进行特征变换作为实验对比分析。该感知器具有两个全连接的层,层之间具有GELU非线性。为探索更优性能且考虑模型大小与时间复杂度问题,加快模型的收敛性,简化模型的主要结构的任务,本文中的Transformer部件未加入多层感知器。后续加入多层感知器后的网络模型作为对比实验,我们标记为CTC
$+ $ ,在第3章第1节中具体说明。2. 实验设计
2.1 数据集的构建
实验中所用数据集来自癌症成像档案(TCIA)提供的AAPMMayo诊所2016年低剂量CT挑战大赛更新后的数据集。该数据集包含从140例患者中收集的3种CT扫描类型,分别为腹部(C系列)、胸部(L系列)和头部(N系列),收集自48、49和42例患者。每个患者的数据包括1/4剂量CT图像(LDCT)和相应的正常剂量CT图像(NDCT)。
本文从中选取了5000对数据,图像大小为256×256,其中90% 作为训练集,10% 作为测试集,C系列选取2400对,L系列选取2400对,N系列选取200对。
2.2 网络训练环境和超参数设定
在网络训练过程中,使用的CPU是Inter(R)Xeon(R)CPU E5-2620 v4 @ 2.10 GHz,GPU是NVIDIA Geforce GTX 1080 Ti。本实验在Windows操作系统下,使用python语言Pytorch深度学习框架实现。
在实验中,本网络的损失函数使用均方误差(MSE)函数,采用Adam优化器对损失函数进行优化,训练次数为100个epoch,初始学习率为2×10-3,下降到2×10-4,训练过程中batch size为6。
2.3 图像质量评价标准
本文使用3种图像质量评价标准,分别为均方根误差(RMSE)E、峰值信噪比(PSNR)R和结构相似度(SSIM)S,对实验中的网络进行定量描述。E跟踪两幅图像之间的绝对像素到像素的损失;R以降噪为目标,是衡量重建图像质量的一种指标;S是一种关注于图像中可见结构的感知度量,是对视觉质量的度量,由亮度、对比度、结构3个模块组成。E,R,S的定义为:
$$ E(x,y) = \sqrt {\frac{{\sum\limits_{s = 1}^N {\sum\limits_{t = 1}^N {{{\left( {{x_{x,t}} - {y_{s,t}}} \right)}^2}} } }}{{{N^2}}}} \text{,} $$ (3) $$ S\left(x,y\right)=\frac{\left(2{\mu }_{x}{\mu }_{y}+{c}_{1}\right)\left(2{\sigma }_{xy}+{c}_{2}\right)}{\left({\mu }_{x}^{2}+{\mu }_{y}^{2}+{c}_{1}\right)\left({\sigma }_{x}^{2}+{\sigma }_{y}^{2}+{c}_{2}\right)},$$ (4) $$R = 10\lg \left( {\frac{{\max (I)}}{{{E^2}}}} \right) \text{,}$$ (5) 其中,公式(3)和公式(4)中x表示低剂量 CT图像,y表示高质量图像,
$N^2 $ 是图像像素总数;公式(5)中$E^2 $ 为均方根误差的平方,$ \max (I) $ 为图片可能的最大像素值;公式(4)中$ {\mu }_{x} $ 是x的平均值,$ {\mu }_{y} $ 是y的平均值,$ {\sigma }_{x}^{2} $ 是x的方差,$ {\sigma }_{y}^{2} $ 是y的方差,$ {\sigma }_{xy} $ 是x和y的协方差,$ {c}_{1},{c}_{2} $ 是常数。3. 实验结果与分析
3.1 低剂量CT图像重建方法比较
实验采用随机选取的5000对数据集,将DNCNN、RED-CNN、BRDNet、Uformer 4个经典网络与CTC网络及CTC
$+ $ 网络进行比较,使用峰值信噪比R、结构相似度S和均方根误差E评估算法的去噪性能和重建的低剂量CT图像的质量。表1给出了不同网络结构对低剂量CT图像去噪结果的定量比较。图4~图6分别为5种网络结构的定性比较,其中图4选择了C系列(肺部)的去噪效果图,图5为图4的局部放大图,图6选择了L系列(腹部)的去噪效果图,图7为图6的局部放大图。
表 1 低剂量CT图像重建实验对比结果Table 1. Experimental comparison of low dose CT image reconstruction指标 DNCNN RED-CNN BRDNet Uformer CTC CTC+ R 31.518 32.325 33.232 33.223 33.574 33.695 S 0.941 0.944 0.954 0.947 0.957 0.958 E 0.028 0.025 0.023 0.023 0.022 0.022 训练时长/h 3.51 9.00 10.12 14.43 13.33 21.66 参数量/G 4.32 6.14 7.83 10.63 9.98 11.62 ![]() 图 5 肺部去噪效果局部放大图(显示窗口为[0,1])Figure 5. Local amplification of lung denoising effect (display window: [0,1])
图 5 肺部去噪效果局部放大图(显示窗口为[0,1])Figure 5. Local amplification of lung denoising effect (display window: [0,1])![]() 图 7 腹部去噪效果局部放大图(显示窗口为[0,1])Figure 7. Local amplification of abdomen denoising effect (display window: [0,1])
图 7 腹部去噪效果局部放大图(显示窗口为[0,1])Figure 7. Local amplification of abdomen denoising effect (display window: [0,1])由表1可见,我们提出的CTC网络模型在R、S和E指标上都优于其他 4种网络模型,表明该模型可以在有效去噪的同时保留更多的细节信息。如图4所示,对于肺部CT图像的处理,CTC网络模型效果最佳。图中红色框区域中该网络肺泡数量最多,且边界最为明显,更有利于医学诊断,详细细节信息可在图5中观察到。如图6所示,对于腹部CT图像的处理,DNCNN和RED-CNN网络去噪效果图过于平滑,细节信息较少。如图中红色框区域所示,CTC网络模型在细节方面显示最为明显,器官的轮廓也最为清晰。详细细节信息可在图7中观察到。CTC与CTC
$+ $ 在数值分析上差值较小,在实验中CTC$+ $ 用时较长,且二者去噪效果图视觉上难于区分优劣。综合考虑时间与性能,我们选取CTC网络模型实现低剂量CT图像去噪。3.2 内部结构规律探索
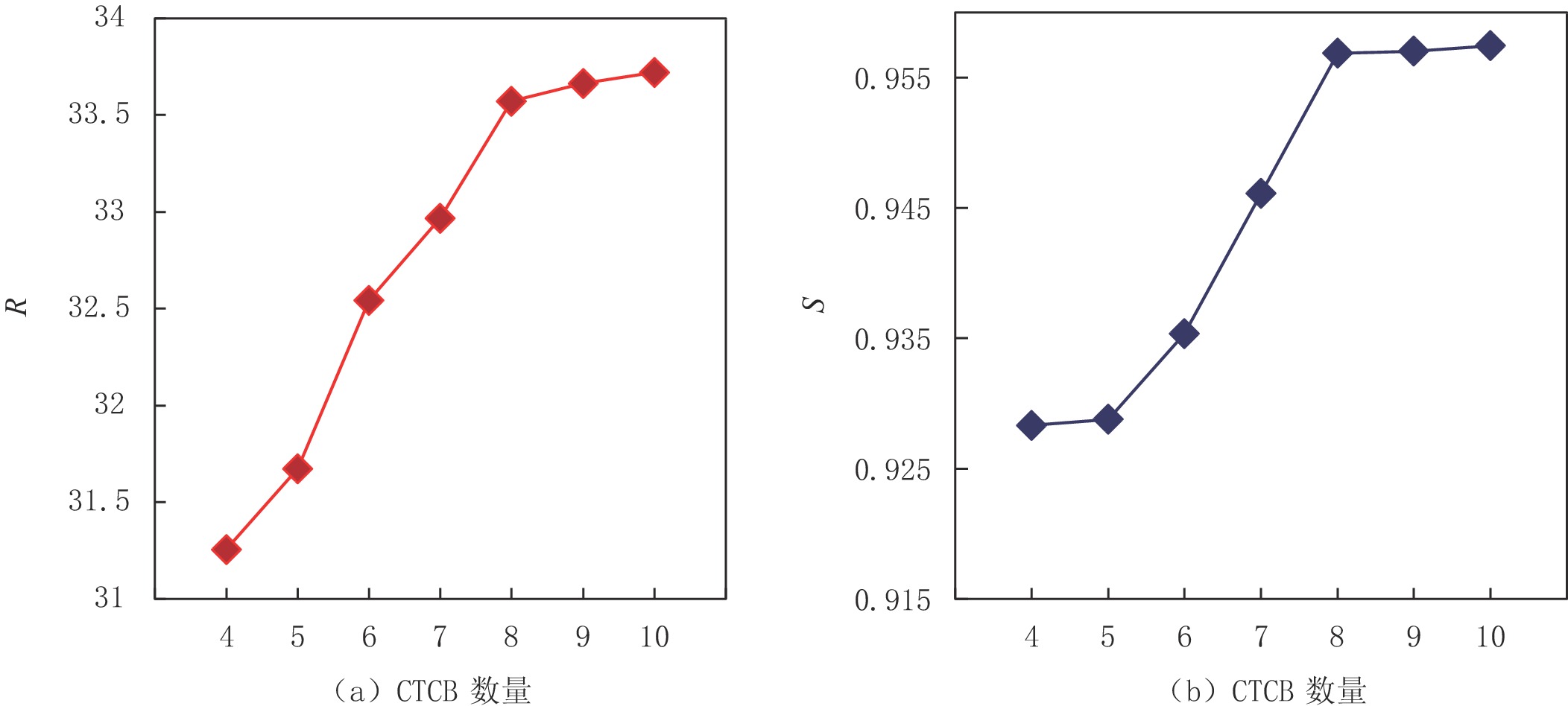
在其他参数一致的情况下,使用峰值信噪比和结构相似度两项客观指标评估CNN和Transformer耦合模块(CTCB)的数量对网络结构的影响。不同CTCB数量下R和S值的折线图如图8(a)和图如图8(b)所示。从中可以看出,网络性能与CTCB数量成正比,且随着层数的增多,网络性能逐渐达到饱和。综合考虑网络复杂性、网络性能与训练时长等因素,我们将该网络的CTCB数量设置为8。
3.3 消融实验
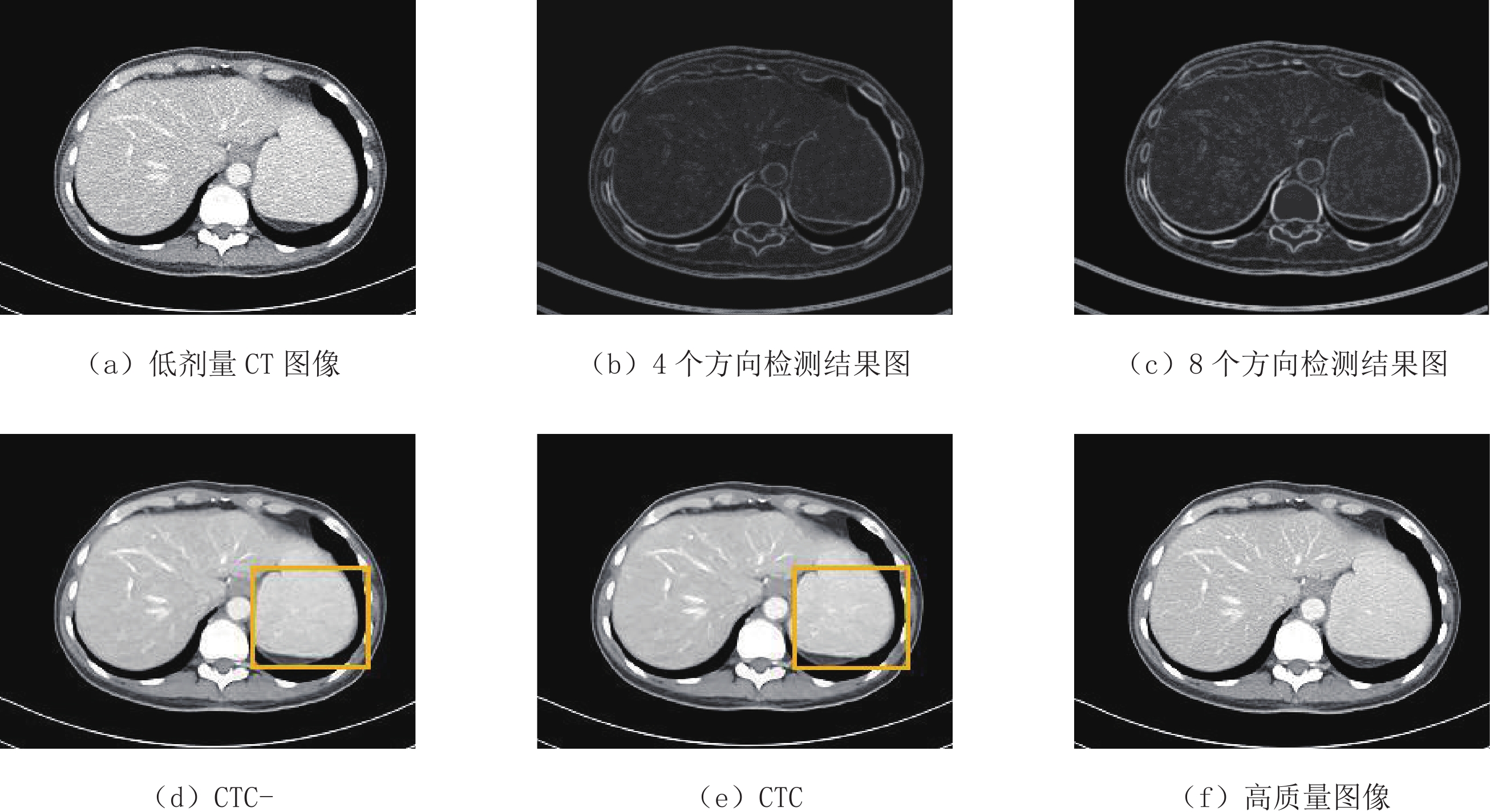
为了讨论CTC网络中图像边缘增强模块对其性能的影响,我们去除CTC网络中的图像边缘增强模块,将其标记为CTC-,并与CTC网络进行定量和定性分析,其结果如表2和图9所示。由表2可见,CTC网络模型的3项评估指标均优于CTC-,其中PSNR指标提升最为明显,表明CTC网络去噪效果更优。图9(e)与图9(d)对应的黄色区域显示CTC网络具有更好的性能,更完备的信息,更适合医学诊断。
表 2 图像边缘增强优化器的影响实验结果Table 2. Effect of image edge enhancement block on experimental results网络模型 评估指标 R S E CTC- 33.310 0.954 0.023 CTC 33.574 0.957 0.022 CTC网络模型中的图像边缘增强模块使用8个方向的索贝尔算子,我们对0°、90°、180°、270° 4个方向的索贝尔算子进行实验与比较。实验结果如图9所示,对于腹部低剂量CT图像,图9(c)中8个方向的索贝尔算子比图9(b)中4个方向的索贝尔算子呈现更多的细节信息,所以我们使用8个方向的索贝尔算子作为图像边缘增强模块。
4. 总结
本文提出的CTC网络综合运用了CNN的局部信息关联能力和Transformer的全局信息捕捉能力,使网络具有CNN的局部感知和参数共享特性的同时具有Transformer的泛化能力。运用滑动窗口机制,更好地利用图像信息且减少了计算量。使用多残差机制有效避免因网络过深而带来的梯度消失和梯度爆炸等问题。网络中的图像边缘增强模块对不同部位的低剂量CT图像中的边缘信息进行提取利用,使得更多的细节信息得以保留。
与现有的4种经典网络对比,本文提出的CTC网络在低剂量CT图像去噪任务中,表现出更优的性能。该网络可以有效去噪的同时保留更完整的图像细节信息,具有一定的医学应用价值。
未来,我们计划基于提出的CTC网络模型进一步探索更优的网络结构,引入多损失机制并将其扩展到其他图像处理任务中。
-
![]()
图 5 肺部去噪效果局部放大图(显示窗口为[0,1])
Figure 5. Local amplification of lung denoising effect (display window: [0,1])
![]()
图 7 腹部去噪效果局部放大图(显示窗口为[0,1])
Figure 7. Local amplification of abdomen denoising effect (display window: [0,1])
表 1 低剂量CT图像重建实验对比结果
Table 1 Experimental comparison of low dose CT image reconstruction
指标 DNCNN RED-CNN BRDNet Uformer CTC CTC+ R 31.518 32.325 33.232 33.223 33.574 33.695 S 0.941 0.944 0.954 0.947 0.957 0.958 E 0.028 0.025 0.023 0.023 0.022 0.022 训练时长/h 3.51 9.00 10.12 14.43 13.33 21.66 参数量/G 4.32 6.14 7.83 10.63 9.98 11.62  下载: 导出CSV
下载: 导出CSV
表 2 图像边缘增强优化器的影响实验结果
Table 2 Effect of image edge enhancement block on experimental results
网络模型 评估指标 R S E CTC- 33.310 0.954 0.023 CTC 33.574 0.957 0.022
下载: 导出CSV
-
[1] BRENNER D J, HALL E J. Computed tomography: An increasing source of radiation exposure[J]. New England Journal of Medicine, 2013, 357(22): 2277−2284.
[2] KOLTAI P J, WOOD G W. Three dimensional CT reconstruction for the evaluation and surgical planning of facial fractures[J]. Otolaryngology-Head and Neck Surgery, 1986, 95(1): 10−15. doi: 10.1177/019459988609500103
[3] MING C, LI L, CHEN Z, et al. A few-view reweighted sparsity hunting (FRESH) method for CT image reconstruction[J]. Journal of X-ray Science and Technology, 2013, 21(2): 161−176. doi: 10.3233/XST-130370
[4] KANG E, MIN J, YE J C. A deep convolutional neural network using directional wavelets for low-dose X-ray CT reconstruction[J]. Medical Physics, 2017, 44(10): e360−e375. doi: 10.1002/mp.12344
[5] PRASOON A, PETERSON K, IGEL C, et al. Deep feature learning for knee cartilage segmentation using a triplanar convolutional neural network[C]//International Conference on Medical Image Computing and Computer-assisted Intervention. Springer, Berlin, Heidelberg, 2013: 246-253.
[6] YANG Q, YAN P, ZHANG Y, et al. Low-dose CT image denoising using a generative adversarial network with wasserstein distance and perceptual loss[J]. IEEE Transactions on Medical Imaging, 2018: 1348−1357.
[7] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 770-778.
[8] YANG D, SUN J. BM3 D-Net: A convolutional neural network for transform-domain collaborative filtering[J]. IEEE Signal Processing Letters, 2017, 25(1): 55−59.
[9] SINGH R, WU W, WANG G, et al. Artificial intelligence in image reconstruction: The change is here[J]. Physica Medica, 2020, 79: 113−125. doi: 10.1016/j.ejmp.2020.11.012
[10] ZHANG K, ZUO W, CHEN Y, et al. Beyond a gaussian denoiser: Residual learning of deep CNN for image denoising[J]. IEEE Transactions on Image Processing, 2016, 26(7): 3142−3155.
[11] CHEN H, ZHANG Y, KALRA M K, et al. Low-dose CT with a residual encoder-decoder convolutional neural network (RED-CNN)[J]. IEEE Transactions on Medical Imaging, 2017, 36(99): 2524−2535.
[12] ZHANG K, ZUO W, ZHANG L. FFDNet: Toward a fast and flexible solution for CNN based image denoising[J]. IEEE Transactions on Image Processing, 2018.
[13] ANWAR S, BARNES N. Real image denoising with feature attention[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 3155-3164.
[14] TIAN C, XU Y, ZUO W. Image denoising using deep CNN with batch renormalization[J]. Neural Networks, 2020, 121: 461−473. doi: 10.1016/j.neunet.2019.08.022
[15] MA Y, WEI B, FENG P, et al. Low-dose CT image denoising using a generative adversarial network with a hybrid loss function for noise learning[J]. IEEE Access, 2020, 8. DOI: 10.1109/ACCESS.2020.2986388.
[16] LIANG J, CAO J, SUN G, et al. Swinir: Image restoration using swin transformer[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 1833-1844.
[17] YUAN K, GUO S, LIU Z, et al. Incorporating convolution designs into visual transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 579-588.
[18] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017. https://doi.org/10.48550/arXiv.1706.03762.
[19] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[J]. arXiv Preprint arXiv: 2010.11929, 2020.
[20] LIU Z, LIN Y, CAO Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 10012-10022.
[21] WANG Z, CUN X, BAO J, et al. Uformer: A general U-shaped transformer for image restoration[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 17683-17693.
[22] HAN K, WANG Y, CHEN H, et al. A survey on vision transformer[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
[23] HUANG G, LIU Z, Van der MAATEN L, et al. Densely connected convolutional networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 4700-4708.
[24] ZHANG J Y, YAN C, HUANG X X. Edge detection of images based on improved Sobel operator and genetic algorithms[C]//2009 International Conference on Image Analysis and Signal Processing. IEEE, 2009: 31-35.
[25] TOLSTIKHIN I O, HOULSBY N, KOLESNIKOV A, et al. MLP-mixer: An all-MLP architecture for vision[J]. Advances in Neural Information Processing Systems, 2021: 34.
-
期刊类型引用(3)
1. 周成,刘洋,邱迎伟,何代均,闫宇,罗敏,雷有缘. 基于最邻近层自监督学习人工智能降噪用于泌尿系结石超低剂量CT. 中国医学影像技术. 2024(08): 1249-1253 .  百度学术
百度学术
2. 李昊岳,薛智元,陆萍萍,张珂. 深度学习用于颞骨CT成像应用进展. 中国医学影像技术. 2024(09): 1432-1435 . 百度学术
3. 李金霞,李静静,肖丹,赵宏波,朱守平. 基于Z轴相关性Zero-Shot Noise2Noise降低低剂量CT图像噪声. 中国医学影像技术. 2024(11): 1764-1768 . 百度学术
其他类型引用(2)
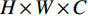


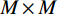
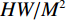
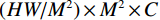
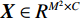
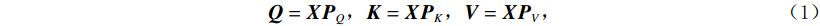
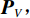
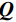
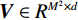
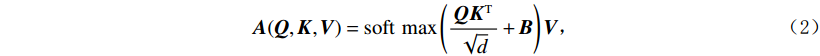
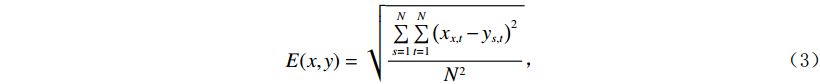
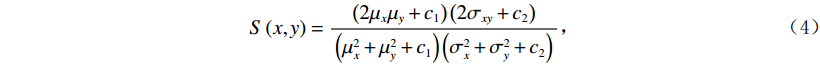
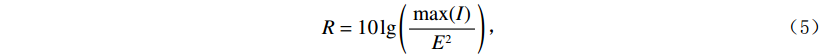
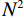
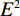
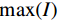
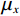
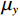
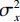
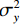
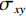
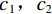




计量
- 文章访问数: 1657
- HTML全文浏览量: 351
- PDF下载量: 361
- 被引次数: 5


